
4.1 개요
프로세스 생성 작업은 매우 많은 시간을 소비하고 많은 자원을 필요로 하는 일
새로 만드는 프로세스가 해야하는 일이 기존 프로세스가 하는 일과 동일하다면 오버헤드 감수하지 말자.
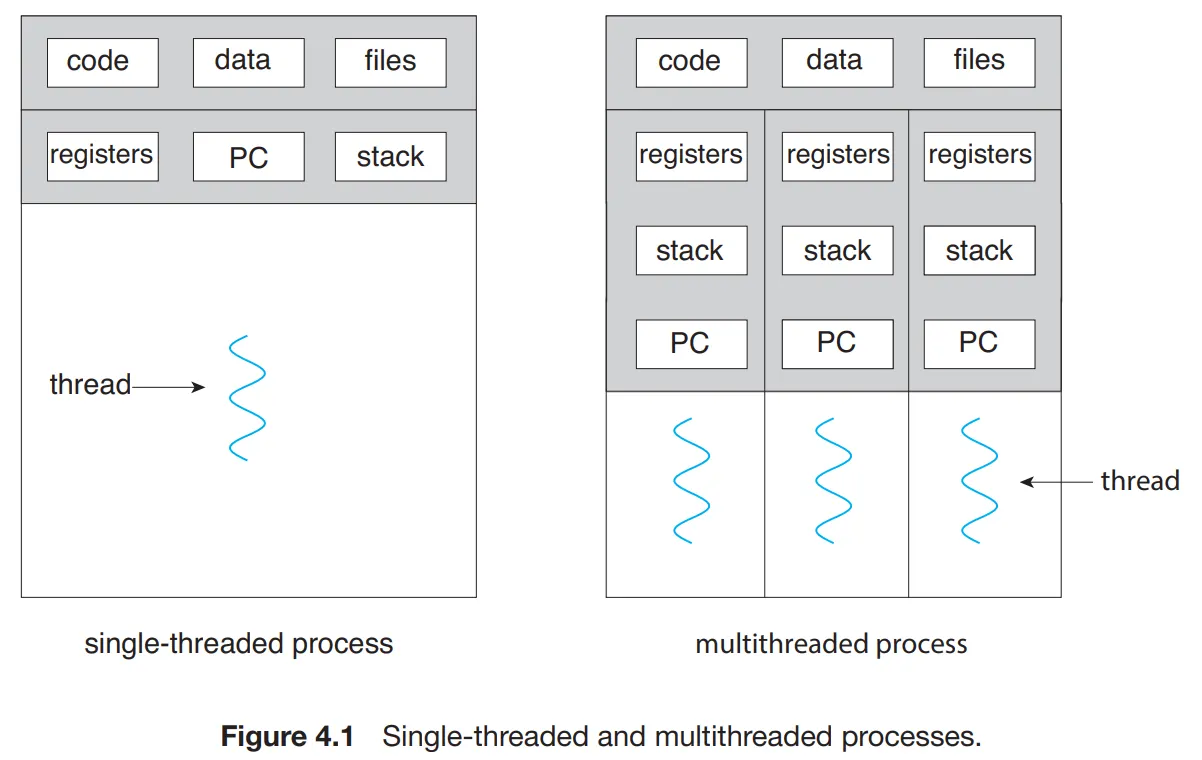
이에 하나의 프로세스에서 다중 스레드를 사용
스레드는 스레드 ID, 프로그램 카운터, 레지스터 집합, 스택으로 구성됨.
같은 프로세스 상에서 코드, 데이터 섹션, 열린 파일이나 신호, 힙도 같이 공유한다.
•
응답성이 좋아진다.
◦
시간이 오래 걸리는 연산이 별도의 비동기적 스레드에서 실행된다면 높은 응답성을 제공
•
자원 공유
◦
프로세스는 공유 메모리와 메시지 전달 기법을 통해서만 자원을 공유할 수 있다.
◦
이러한 기법은 프로그래머에 의해 처리됨. 그러나 스레드는 그들이 속한 프로세스의 자원들과 메모리를 공유한다.
◦
한 응용 프로그램이 같은 주소 공간 내에 여러 개의 다른 작업을 하는 스레드를 가질 수 있다.
•
경제성
◦
프로세스 생성을 위한 메모리와 자원 할당은 비용이 많이 든다.
◦
스레드를 생성하고 문맥을 교환하는 것이 더욱더 경제적
•
규모 적응성
◦
각각의 스레드가 다른 처리기에서 병렬로 수행된다.
4.2 다중 코어 프로그래밍
각 코어는 운영체제에 별도의 CPU로 보인다.
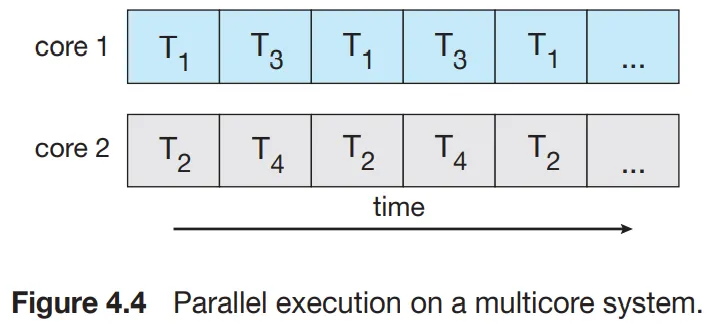
병행성과 병렬성은 다르다
병행성 : 모든 작업이 진행되게 하여 둘 이상의 작업을 지원한다.
병렬성: 둘 이사의 작업을 동시에 수행할 수 있다.
→ 병렬성 없이 병행성을 가질 수 있다.
프로그래밍 도전과제
1.
태스크 인식
a.
독립된 병행 가능 태스크로 나눌 수 있는 영역을 찾아야한다. 서로 독립적이고 개별 코어에서 병렬 실행 가능해야한다.
2.
균형
a.
찾아진 부분들이 전체 작업에 균등한 기여도를 가지는 태스크로 나누는 것도 중요하다.
3.
데이터 분리
a.
태스크가 접근하고 조작하는 데이터 또한 개별 코어에서 사용할 수 있도록 나누어져야한다.
4.
데이터 종속성
a.
태스크가 접근하는 데이터는 태스크들 간의 종속성이 없는지 검토.
b.
태스크 수행의 동기화를 잘 해야한다.
5.
시험 및 디버깅
a.
병렬로 실행되면 다양한 실행 경로가 존재한다.
b.
따라서 멀티스레딩 디버깅은 훨씬 어렵다.
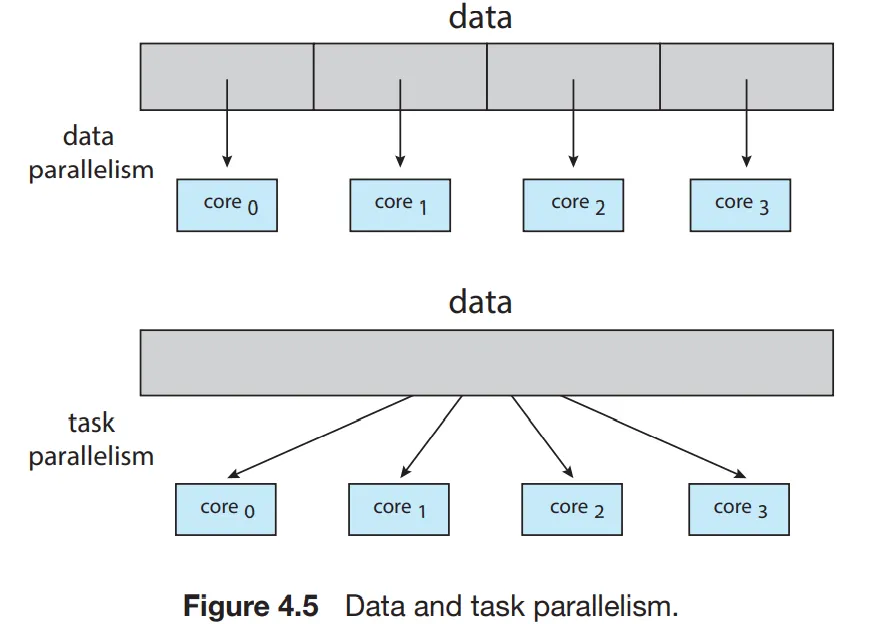
병렬 실행의 유형
1.
데이터 병렬 실행
a.
동일한 데이터의 부분집합을 다수의 계산 코어에 분배한다.
2.
태스크 병렬 실행
a.
데이터가 아니라 태스크를 다수의 코어에 분배. 각 스레드는 고유의 연산을 실행함.
다중 스레드 모델
스레드는 사용자 스레드와 커널 스레드로 나뉜다.
사용자 스레드는 커널 위에서 지원된다. 즉 커널 스레드 1개가 여러 사용자 스레드를 처리한다.
커널 스레드는 운영체제에 의해 직접 지원되고 관리됨.
이에 따라 사용자 스레드와 커널 스레드는 서로 연관성이 있다.
다대일 모델
많은 사용자 수준 스레드를 하나의 커널 스레드로 사상한다.
스레드 관리는 사용자 공간의 스레드 라이브러리에 의해 행해진다. 이에 따라 오에스에서 지원하는 문맥 교환이 없으니 효율적이다. 하지만 한 스레드가 봉쇄형 시스템 콜을 할 경우, 전체 프로세스가 봉쇄됨.
한 번에 하나의 스레드만이 커널에 접근할 수 있기에, 다중 스레드가 다중 코어 시스템에서 병렬로 실행될 수 없다.
일대일 모델
사용자 스레드를 각각 하나의 커널 스레드로 사상.
하나의 스레드가 봉쇄적 시스템 콜을 호출해도 다른 스레드가 실행될 수 있기에 병렬성을 제공한다.
다중 처리기에서 다중 스레드가 병렬로 실행되는 것을 허용한다.
다대다 모델
사용자 스레드를 커널 스레드로 멀티플렉스한다.
구현하기가 어렵다. 대부분의 시스템에서 처리 코어 수가 증가함에 따라 커널 스레드 수를 제한하는 것의 중요성이 줄어들었다. 대부분의 운영체제는 일대일 모델을 사용. 일부 현대 병행 라이브러리는 개발자가 태스크를 식별하면 다대다 모델을 사용하여 매핑될 수 있도록 지원.
스레드 라이브러리
프로그래머에게 스레드를 생성하고 관리하기 위한 API를 제공한다.
1.
완전히 사용자 공간에서만 라이브러리를 제공하는 것
a.
라이브러리의 모든 코드와 자료구조는 사용자 공간에 존재.
b.
라이브러리의 함수를 호출하는 것은 시스템 콜이 아니라 사용자 공간의 지역함수를 호출하게 된다.
2.
커널 수준 라이브러리를 구현하는 것
a.
라이브러리를 위한 코드와 자료구조는 커널 공간에 존재한다.
종류
1.
POSIX - 사용자 또는 커널 수준 라이브러리
2.
Windows - 커널 수준 라이브러리
3.
Java - 자바 프로그램에서 직접 스레드 생성과 관리를 가능하게 함. JVM구현은 호스트 운영체제에서 실행되기 때문에 통상 시스템의 스레드 라이브러리를 이용하여 구현된다.
→ POSIX와 Window는 전역 변수로 선언된 데이터, 즉 함수 외부에 선언된 데이터는 같은 프로세스에 속한 모든 스레드가 공유한다.
•
비동기 스레드
◦
부모가 자식을 생성한 후 부모는 자신의 실행을 재개한다.
◦
서로 간의 독립적이기에 스레드 간의 데이터 공유가 거의 없다.
•
동기 스레드
◦
부모는 자식들의 작업이 끝날 때까지 실행을 계속할 수 없다.
◦
스레드 사이의 상당한 양의 데이터 공유를 수반한다.
Pthreads
•
스레드의 동작에 관한 명세일 뿐이지, 자체를 구현한 것은 아니다.
•
운영체제 설계자들이 알아서 구현할수 있다.
•
음이 아닌 정수의 합을 구하는 프로그램
별도의 스레드는 지정된 함수에서 실행을 시작함
하나의 제어 스레드가 main()에서 시작한다. 약간의 초기화 후에 main은 runner함수에서 시작하는 두 번째 스레드를 생성
#include<pthread.h>
#include <stdio.h>
#include<stdlib.h>
int sum;
void *runner(void *param);
int main(int argc, char *argv[]){
pthread_t tid;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_create(&tid, &attr, runner, argv[1]);
pthread_join(tid, NULL);
printf("sum = %d\n", sum);
}
void *runner(void *param)
{
int i,upper = atoi(param);
sum = 0;
for(i=1; i<=upper; i++)
sum += i;
pthread_exit(0);
}
C
복사
•
pthread_attr_t : 스레드를 위한 속성
◦
pthread_attr_init(&attr) : 속성을 지정하지 않았기에 디폴트 속성
•
pthread_create(): 스레드 생성
•
pthread_join() : 합산 스레드가 종료하기를 부모스레드가 기다린다.
•
pthread_exit(): 스레드의 종료
pthread_join()함수를 사용하여 여러 개의 스레드를 기다리는 간단한 방법은 for반복문으로 둘러싸는 것
pthread_t workers[NUM_THREADS];
for(int i=0; i < NUM_THREADS; i++)
pthread_join(workers[i], NULL);
C
복사
JAVA 스레드
1.
Thread 클래스에서 파생된 새 클래스를 만들고 run()메소드를 오버라이드
2.
Runnable인터페이스를 구현하는 클래스를 정의
class Task implement Runnable{
public void run(){
System.out.println("I am a thread.");
}
}
Thread worker = new Thread(new Task());
worker.satart();
try{
worker.join();
} catch(InterruptedException ie){}
Java
복사
새 Thread 객체에 대해 start()를 호출하면,
1.
메모리가 할당되고 JVM내에 새로운 스레드가 초기화
2.
run()메소드를 호출하면 스레드가 JVM에 의해 수행될 자격을 갖게 한다.
a.
start메소드가 run메소드를 호출함.
JAVA Executor 프레임워크
Executor 인터페이스를 구현하자.
Runnable 객체가 인자로 전달되는 execute() 메소드를 정의해야함.
Executor service = new Executor;
service.execute(new Task());
Java
복사
Executor 프레임워크는 생산자-소비자 모델을 기반으로 함
Runnable 인터페이스를 구현하는 작업이 생성되고 이러한 작업을 실행한느 스레드가 이를 소비한다.
스레드 생성을 실행에서 분리할 뿐만 아니라 병행하게 실행되는 작업 간의 통신 기법을 제공
자바는 전역 변수라는 개념이 없기 때문에, Runnable을 구현한 클래스에서 리턴할 수가 없다.
이에 Runnable클래스에 기능을 추가한 Callable인터페이스를 구현해서 넘겨주면 된다.
Callable 인터페이스는 Future객체를 반환한다.
class Summation implements Callable<Integer>
{
private int upper;
public Summation(int upper){
this,upper = upper;
}
public Integer call(){
int sum = 0;
for(int i=1; i<= upper; i++) sum += i;
return new Integer(sum);
}
}
public class Driver{
public static void main(String[] args){
int upper = Integer.parseInt(args[0]);
ExecutorService pool = Executors.newSinglethreadExecutor();
Future<Integer> result = pool.submit(new Summabtion(upper));
try{
System.out.println("sum = " + result.get());
}catch(InterruptedException | ExecutionException ie){ }
}
}
Java
복사
•
submit() : Callable 객체를 넘기고 결과를 반환받는다.
•
Future 객체의 get(): 메소드 호출하면 결과를 기다린다.
•
스레드 생산과 스레드가 만든 결과를 분리한다.
◦
결과를 확인하기 전에 스레드 종료를 기다리는 대신 부모는 결과가 가용해지는 것만 기다린다.
암묵적 스레딩
•
스레딩의 생성과 관리 책임을 응용 개발자로부터 컴파일러와 실행시간 라이브러리에게 넘겨주는 것
스레드 풀
문제가 많다.
•
서비스할 때마다 스레드를 생성하는데 소요되는 시간
◦
스레드가 일만 끝나면 바로 폐기될 것이다.
◦
모든 요청마다 스레드를 만들면 비용이 많이 든다.
◦
시스템에서 동시에 실행할 수 있는 최대 스레드 수가 몇 개까지 가능할 수 있는 것인지 한계를 정해야함.
스레드 풀은 아예 일정한 수의 스레드들을 미리 풀로 만들어둔다.
일감 없이 기다리게 된다.
서버는 스레드를 생성하지 않고 요청을 받으면 대신 스레드 풀에 제출하고 추가 요청 대기를 재개
풀에 가능한 스레드가 있으면 깨어나고, 요청이 즉시 서비스 됨. 가용한 쓰레드가 없으면 작업이 대기된다.
장점
•
새 스레드를 만들어주기보다 기존 스레드로 서비스해주는 것이 종종 더 빠르다.
•
스레드 풀은 임의 시각에 존재할 스레드 개수에 제한을 둔다. 많은 수의 스레드를 병렬 처리할 수 없는 시스템에 도움이 됨.
•
태스크를 생성하는 방법을 태스크로부터 분리하면 태스크 실행을 다르게 할 수 있다. 태스크를 일정 시간 후에 실행하도록 스케줄하거나 주기적으로 실행 가능
◦
원래는 태스크가 생성되면 바로 실행되니까 생성과 실행이 합쳐져있다.
JAVA 스레드 풀
•
newSingleThreadExecutor() : 크기가 1인 스레드 풀을 생성
•
newFiexedThreadPool(int size): 지정된 수의 스레드가 있는 스레드 풀을 생성
•
newCachedThreadPool(): 많은 경우 스레드를 재사용하는 무제한 스레드 풀을 생성
public class ThreadPoolExample
{
public static void main(String[] args]){
int numTasks = Integer.parseInt(args[0].trim());
ExecutorService ppol = Executor.newCachedThreadPool();
for(int i=0; i<numTasks; i++){
pool.executor(new Task());
}
pool.shutdown();
}
}
Java
복사
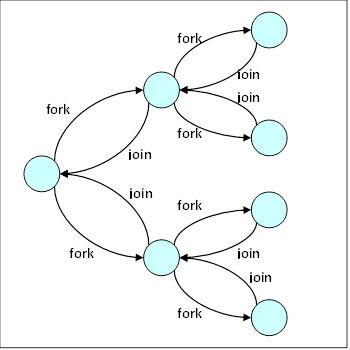
Fork Join
부모 스레드가 하나 이상의 자식 스레드를 생성한 다음. 자식의 종료를 기다린 후 join하고, 그 시점부터 자식의 결과를 확인하고 결합할 수 있다. 라이브러리는 생성되는 스레드 수를 관리하며 스레드에 작업 배정을 책임진다.
Java에서의 Fork Join
새로운 기본 풀인 ForkJoinPool을 도입하여 추상 기본 클래스 ForkJoinTask를 상속하는 작업을 배정받을 수 있다.
ForkJoinPool pool = new ForkJoinPool();
int[] array = new int[SIZE];
SumTask task = new SumTask(0,SIZE -1 , array);
int sum = pool.invoke(task);
public class SumTask extends RecursiveTask<Integer>
{
static final int THRESHOLD = 1000;
private int begin;
private int end;
private int[] array;
public SumTask(int begin, int end, int[]array){
this.begin = begin;
this.end = end;
this.array = array;
}
protected Integer compute(){
if(end - begin < THRESHOLD){
int sum = 0;
for(int i = begin; i<= end; i++)
sum += array[i];
return sum;
}
else {
int mid = (begin + end) / 2;
SumTask leftTask = new SumTask(begin, mid, array);
SumTask rightTask = new SumTask(mid + 1, end, array);
leftTask.fork();
rightTask.fork();
return rightTask.join() + leftTask.join();
}
}
}
Java
복사
완료되면 첫번째 invoke에 대한 호출은 배열의 합계를 반환한다.
충분히 작은 크기여서 추가 작업을 만들 필요가 없을 때를 정한다. THRESHOLD;
4.6 스레드와 관련된 문제들
Fork() 및 Exec()시스템 콜
한 프로그램의 스레드가 fork()를 호출하면, 새로운 프로세스는 모든 스레드를 복제해야하는가 아니면 한 개의 스레드만 가지는 프로세스여야하는가.
UNIX는 이 두가지 버전의 fork()를 다 제공함.
어떤 스레드가 exec()시스템 콜을 부르면 exec()의 매개변수로 지정된 프로그램이 모든 스레드를 포함한 전체 프로세스를 대체시킨다. →그냥 전체 스레드가 엎어지고 새로운 프로그램이 된다.
fork()를 부르자마자 exec을 부른다면 모든 스레드를 복제해서 만들어주는 것은 불필요. 어차피 다시 다 대체할 것이기 대문에. 이 경우에는 fork()시스템 콜을 호출한 스레드만 복사해주는 것이 적절.
그렇지 않다면 모든 스레드를 복제해야한다.
신호처리
모든 신호는 다음과 같은 형태로 전달된다.
1.
특정 이벤트가 일어나야 생성
2.
생성된 신호가 프로세스에 전달
3.
신호가 전달되면 반드시 처리되어야 한다.
동기식 신호
•
불법적인 메모리 접근, 0으로 나누기 등.
비동기식 신호
•
실행 중인 프로세스 외부로부터 발생
•
프로세스를 강제 종료시키거나 타이머가 만료되는 경우가 포함.
신호 처리기에는 다음과 같은 종류가 있다.
•
디폴트 신호 처리기
•
사용자 정의 신호 처리기
단일 스레드 프로그램에서의 신호 처리는 간단하다.
다중 스레드에서는 어느 스레드에 신호를 전달해야하는가?
•
신호가 적용될 스레드에게 전달
•
모든 스레드에게 전달
•
몇몇 스레드들에게 선택적으로 전달
•
특정 스레드가 모든 신호를 전달받도록 지정
동기식 신호는 그 신호를 야기한 스레드에 전달되어야하고 다른 스레드에 전달되면 안된다.
비동기식 신호의 경우는 명확하지 않다.
스레드 취소
취소되어야할 스레드를 target thread라고 부른다.
비동기식 취소 : 한 스레드가 즉시 target thread를 강제 종료시킨다.
지연 취소 : target thread가 주기적으로 자신이 강제 종료될지를 점검.
비동기식으로 취소하면 필요한 시스템 자원을 다 사용 가능한 상태로 만들지 못할 수도 있다.
지연 취소의 경우에는 목적 스레드를 취소해야 한다고 표시하지만, 실제 취소는 목적 스레드 자신이 한다. 따라서 안전하게 스레드를 취소할 수 있다.
스레드-로컬 저장 장치
각 스레드가 자기만 엑세스할 수 있는 데이터를 가져야할 필요가 있다. Thread-local storage(TLS)라고 함.
TLS를 지역변수와 혼동하기 쉽다. 지역 변수가 하나의 함수가 호출되는 동안에만 보이지만 TLS는 전체 함수 호출에 걸쳐 보인다.