
SQL 중심적인 개발의 문제점
데이터베이스 세계의 헤게모니 - 관계형 DB
지금 시대는 객체를 관계형 DB에 관리하는 시대
무한 반복적인 CRUD
패러다임의 불일치
관계형 DB - 데이터를 잘 정규화해서 보관하는게 목표
구현체 - 속성과 기능이 묶여서 잘 캡슐화해서 쓰는게 목표
SQL 변환 → SQL을 짜야한다. 누가하냐? → 개발자가 한다.
객체와 관계형 데이터베이스의 차이
상속 : 객체는 있고 DB는 없다
Album을 분해새서 ITEM과 ALBUM 테이블에 각각 넣는다.
Album을 조회하고 싶으면, ITEM과 Album 조인 쿼리를 만든다.
조회할 때 엄청 복잡해진다.
연관관계: 레퍼런스, DB는 PK와 FK로 Join해서 함
객체는 참조를 사용
테이블은 외래 키를 사용 Joint on M.TEAM_ID = T.TEAM_ID
객체는 단방향, 테이블은 양방향으로 참조를 할 수 있다.
객체는 자유롭게 객체 그래프를 탐색할 수 있어야한다.
다만 SQL에서는 처음 실행하는 SQL에 따라 탐색 범위가 결정된다.
이러한 문제 때문에 엔티티에 대한 신뢰성 문제가 발생
그렇다고 해서 모든 객체를 미리 로딩할 수는 없다.
데이터 타입
Member member1 = memberDAO.getMember(id1);
Member member2 = memberDAO.getMember(id1);
member1 ≠ member2;
내가 객체지향적으로 모델링할수록 매핑 작업만 늘어난다.
객체를 자바 컬렉션에 저장 하듯이 DB에 저장할 수 없을까?
JPA 소개
ORM 프레임워크가 관계형 데이터베이스와 객체가 매핑해준다.
저장 : jpa.persist(member)
조회: jpa.find(memberId)
수정: member.setName("변경할 이름)
삭제: jpa.remove(member)
패러다임 불일치를 해결해준다
상속관계
슈퍼타입, 서브타입 관계를 모델링했다.
저장: jpa.persist(album)
→ Insert Into Item ....
→ Insert into Album ...
조회: jpa.find(Album.class, albumId)
→ 조인해서 들고와준다.
연관관계
연관관계에 있는 거를 알아서 참조할 수 있다.
같은 트랜잭션에서 조회한거는 같다고 조회가 된다.
중간 단계를 쓰면 버퍼링 / 캐싱
성능 최적화 기능
1차 캐시와 동일성 보장
캐싱을 하고 있으니까, SQL을 여러 번 안해도 된다.
트랜잭션을 지원하는 쓰기 지연
JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
트랜잭션 커밋하기 전에만 쏘면 된다.
지연로딩과 즉시 로딩
지연로딩: Member객체만 꺼내올 때는 Member만 들고옴. Team에 대한 값이 필요할 때 쿼리를 날리는 것
즉시로딩: 만약 Member와 Team을 항상 같이 조회하면 함께 들고올 수 있다.
실제로 지연로딩을 다 한다음에 즉시로딩이 필요하면 즉시로딩을 한다.
JPA시작
필요한 Library
•
hibernate - hibernate-entitymanager
•
h2database
필요한 설정
•
persistence.xml
•
DB연결 정보를 넣어줘야한다.
JPA 동작
•
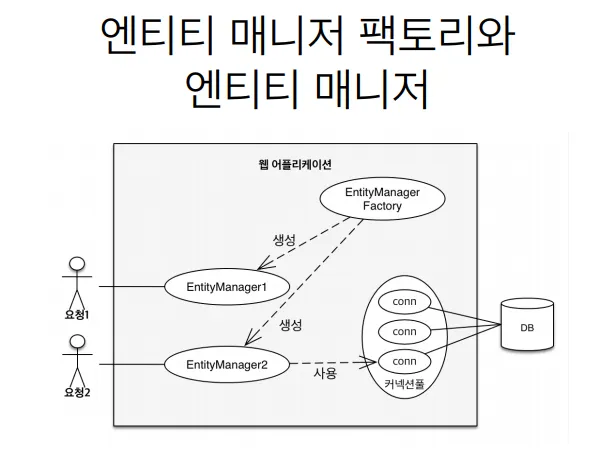
persistence.xml에서 설정정보를 조회하고 EntityManagerFactory를 생성해서
•
EntityMangerFactory에서 EntityManager들을 생성한다.
EntityManagerFactory → 하나만 생성해서 애플리케이션 전체에서 공유
EntityManager → 쓰레드간에 공유 X
JPA의 모든 데이터변경은 트랜잭션 안에서 실행(조회는 된다)
JPQL
•
엔티티 객체를 중심으로 개발
•
문제는 검색 쿼리, 검색을 할 때도 엔티티 객체를 대상으로 검색
•
모든 DB데이터를 객체로 변환해서 검색하는 것은 불가능.
영속성 관리
JPA에서 가장 중요한 2가지
•
객체와 관계형 데이터베이스 매핑하기
•
영속성 컨텍스트
영속성 컨텍스트 - 엔티티를 영구 저장하는 환경
EntityManager.persist(entity)
엔티티를 영속성 컨텍스트라는데에 저장하는거다.
영속성 컨텍스트 - 논리적인 개념
엔티티 매니저를 통해 영속성 컨텍스트에 접근
J2EE,스프링 프레임워크 같은 컨테이너 환경
엔티티 매니저 : 영속성 컨텍스트 = N : 1
엔티티의 생명 주기
•
비영속(new) : 생성만 한 상태
•
영속(managed) : em.persist(member) → 영속성 컨텍스트에 저장하기.
•
준영속(detached)
•
삭제(removed)
영속성 컨텍스트의 이점
중간에 있으면 좋은 점: 버퍼링 , 캐싱
•
1차 캐시
•
동일성 보장
•
트랜잭션을 지원하는 쓰기 지연
•
변경 감지
•
지연로딩
1차 캐시에서 조회
DB에 먼저 가지 않고, 1차 캐시에서 먼저 조회한다.
캐시에 없다면 DB에 가서 들고온 다음에 영속성 컨텍스트에 집어넣는다.
큰 도움은 안된다. 트랜잭션 단위로 영속성 컨텍스트에서 유지가 되기 때문.
영속 엔티티의 동일성 보장
자바 컬렉션 처럼 == 비교하면 True가 반환된다.
트랜잭션을 지원하는 쓰기 지연
트랜잭션을 커밋하는 순간에 데이터베이스에 Insert SQL을 보냄
엔티티 수정(변경 감지)
1차 캐시에는 엔티티가 있고 스냅샷이라는게 있다.
스냅샷 - 영속성 컨텍스트 안에 처음 들어왔을 때의 상태를 저장해놓은 것
flush하게 되면, 변경된 사항을 스냅샷이랑 비교해서 commit을 하는 거임
플러시
영속성 컨텍스트의 변경 내용을 DB에 반영
•
변경 감지
•
수정된 엔티티 쓰기 지연 SQL 저장소에 등록
•
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
플러시 되는 상황
•
em.flush()
•
트랜잭션 커밋
•
JPQL 쿼리 실행
플러시는!
영속성 컨텍스트를 비우지 않음
영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화
트랜잭션이라는 작업 단위가 중요 → 커밋 직전에만 동기화하면 됨
준영속 상태
영속 → 준영속
영속성 컨텍스트에서 분리, 기능을 사용하지 못함.
준영속 상태로 만드는 법
•
em.detatch(entity) ⇒ 특정 엔티티만 detach
•
em.clear() ⇒ 영속성 컨텍스트를 초기화
•
em.close() ⇒ 영속성 컨텍스트를 닫는다.
엔티티 매핑
객체와 테이블 매핑
객체와 테이블 매핑: @Entity, @Table
필드와 컬럼 매핑: @Column
기본 키 매핑: @Id
연관관계 매핑: @ManyToOne, @JoinColumn
@Entity
•
기본 생성자가 필수
•
final 클래스, enum, interface, inner 클래스 사용 X
•
저장할 필드에 final 사용 X
데이터베이스 스키마 자동 생성
DDL을 애플리케이션 실행 시점에 자동 생성
테이블 중심 → 객체 중심
데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
이렇게 생성된 DDL은 개발 장비에서만 사용
생성된 DDL은 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용
create: 기존 테이블 삭제 후 다시 생성
create-drop: create와 같으나 종료 시점에 Drop
update: 변경분만 반영 → 컬럼값을 추가하고 싶을 때(Alter문이 날라간다.) 근데 컬럼을 지우는 건 안됨. 단 운영 DB에는 사용하면 안된다.
validate: 엔티티와 테이블이 정상 매핑 되었는지
none: 아무것도 없다.
주의할 점
개발 초기 단계 - create 또는 update
테스트 서버 - update 또는 validate , create→ 데이터가 날라가니까 절대 쓰면 안됨
스테이징과 운영 서버 - validate, none
가급적으로 치지마라. 시스템이 자동으로 Alter하게 놔두지 말자....
제약조건 추가
회원 이름은 필수, 10자 초과 X
→ @Column(nullable = false, length = 10)
유니크 제약 조건 추가 : 유니크는 컬럼에 대해서 각 필드가 중복된 값이 되면 안된다.
DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향X
필드와 컬럼 매핑
•
TEMPORAL → DATE를 어떻게 매핑할거냐
•
LOB → BLOB, CLOB 매핑
Column
•
name: 필드와 매핑할 테이블의 컬럼 이름
•
insertable, updatable: 등록, 변경 가능 여부
•
nullable = false
기본 키 매핑
직접 할당: @ID만 사용
자동 생성 : @GeneratedValue
GeneratedValue
•
startegy = GenerationType.Identity
id생성을 DB에 위임하는 것
•
Sequence
Oracle, @SequenceGenerator가 필요하다.
•
Auto
방언에 따라 자동 지정 → 기본 값이다.
•
Table
키 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략
식별자 전략
먼 미래까지 변하지 않을 키를 어떻게 찾냐
자연키를 찾기 어려우니 대체키를 사용하자. 비즈니스와 전혀 상관없는 키
권장: Long형 + 대체키 + 키 생성전략 사용
연관관계
방향: 단방향, 양방향
다중성: 다대일, 일대다, 일대일, 다대다 이해
연관관계의 주인: 객체 양방향 연관관계는 관리인이 필요
연관관계가 필요한 이유
객체지향 설계의 목표는 자율적인 객체들의 협력 공동체를 만드는 것이다.
단방향 연관관계
@Entity
public class Member{
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
Java
복사
양방향 연관관계와 연관관계의 주인
어려운 거 - 영속성 컨텍스트 & 양방향 연관관계와 연관관계의 주인
테이블 : JOIN하면 된다.
테이블의 연관관계 → 외래키 하나로 양방향이 다 있는거다.
문제는 객체: 멤버가 Team을 가졌으나, Team에는 Member로 갈 수가 없었다.
반대편에는 ~~가 걸려있다. mappedBy
객체는 가급적이면 단방향이 좋다.
양방향
단방향이 2개다!
회원 → 팀 연관관계 1개
팀 → 회원 연관관계 1개
객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단방향 관계 2개다
객체를 양방향으로 참조하려면 단방향 연관관계를 2개 만들어야함.
주인관계
update할 때 문제가 생긴다.
Member에 Team값을 바꿔야하냐? Team에 있는 members를 바꿔야하냐?
DB값은 TEAM_ID, 외래키 값만 바꾸면 된다.
과연 어떤 걸로 외래키를 관리할거냐? → 객체의 두 관계 중 하나를 연관관계의 주인으로 지정
연관관계의 주인만이 외래 키를 관리(등록,수정)
주인이 아닌쪽은 읽기만 가능
누구를 주인으로?
외래키가 있는 곳을 주인으로 정해라!!
Member: Member_ID(PK), TEAM_ID(FK), USERNAME
TEAM: TEAM_ID(PK)
이렇게 있을 때 Member.team이 연관관계의 주인
이렇게 해야 햇갈리지 않는다.
많이 하는 실수
연관관계에 주인에 값을 꼭 넣자
주인이 아닌 곳에 값을 집어넣는 사례
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
team.getMembers().add(member);
em.persist(member);
Java
복사
주인에 값을 집어넣는 사례
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
Java
복사
양방향 매핑을 할 때?
그냥 양쪽에 값을 다 넣어주는게 맞다.
객체지향 적으로 생각해보면 양쪽 다 넣어주는게 맞다.
양쪽 다 안 넣어주면 문제가 생긴다.
•
바로 쿼리가 날라가는게 아니라 1차 캐시에 일단 저장되는 거기 때문에
•
같은 트랜잭션 안에서 주인의 역방향으로 조회를 했을 때, 1차 캐시에는 아무것도 없다.
•
따라서 빈 게 나올 수 있다.
순수 객체 상태를 고려해서 항상 양쪽에 값을 설정하자
연관관계 편의 메소드를 생성하자 → 양쪽에 둘 다 넣어주는 메소드를 넣는
public void setTeam(Team team){
this.team = team;
team.getMembers().add(this);
}
Java
복사
연관관계 편의 메소드는 근데 getter, setter에 안 넣는다. 차라리 이름을 바꿈
changeTeam()과 같은 메소드를 설정
양방향 매핑시에 무한 루프를 조심하자
toString(), lombok, JSON 생성 라이브러리
toString()의 경우 라이브러리를 사용해서 자동으로 해버리면, 객체가 객체를 서로서로 호출함.
컨트롤러에서 엔티티를 response로 바로 보내버릴 때, JSON생성 라이브러리가 toString을 호출하면서 무한루프 걸린다.
lombok에서 toString만드는거를 쓰지말자!!
JSON 생성 라이브러리 - 컨트롤러에는 엔티티를 절대 반환하지 마라.
왜냐 API를 갖다쓰는 입장에서 API 스펙이 바뀌기 때문에 엔티티를 반환하면 안된다.
양방향 매핑 정리
처음엔 단방향 매핑만으로도 이미 연관관계 매핑은 완료
양방향 매핑은 반대 방향으로 조회 기능이 추가된 것 뿐
JPQL에서 역방향으로 탐색할 일이 많음
단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 됨.
다양한 연관관계 매핑
고려해야할 것
•
다중성
•
단방향, 양방향
•
연관관계의 주인
데이터베이스 기준의 다중성을 기준으로 고민하면 됨.
애매하면, 반대로 생각하자
다중성
다대일
일대다
일대일:
다대다: 실무에서 쓰지 말자!
단방향 양방향
테이블
•
외래 키 하나로 양쪽 조인 가능
•
사실 방향이라는 개념이 없음
객체
•
참조용 필드가 있는 쪽으로만 참조 가능
•
한쪽만 참조하면 단방향
•
양쪽이 서로 참조하면 양방향 : 단방향이 두 개다
연관관계의 주인
테이블은 외래 키 하나로 두 테이블이 연관관계를 맺음
객체 양방향 관계는 사실 참조가 2군데
객체 양방향 관계는 참조가 2군데 있음. 둘 중 테이블의 외래 키를 관리할 곳을 지정해야함
연관관게의 주인: 외래 키를 관리하는 참조
주인의 반대편: 외래 키에 영향을 주지 않음. 단순 조회
다대일(N:1)
다 쪽에 외래키가 가야함
반대쪽이 추가한다고 하더라도 테이블에 영향을 주지 않는다. 즉, 일에 필드를 추가함.
일대다(1:N)
일이 연관관계의 주인
이 모델은 권장하진 않다.

근데 DB설계상 다 쪽에 외래키가 무조건 있어야함.
Team의 List members를 바꿨을 때 , Member라는 테이블의 FK(TEAM_ID)를 바꿔줘야함.
객체와 테이블의 차이 때문에 반대편 테이블의 외래 키를 관리하는 특이한 구조
JoinColumn을 꼭 사용해야함. 그렇지 않으면 조인 테이블 방식을 사용함
그냥 다대일 양방향 매핑을 사용하자
일대일 (1:1)
주 테이블이나 대상 테이블 중에 외래 키 선택 가능
•
주 테이블에 외래 키
•
대상 테이블에 외래 키
외래 키에 데이터베이스 유니크 제약조건 추가



멤버가 여러 개의 Locker를 들고 있을 수 있도록 바뀐다면? ⇒ 밑에꺼
반대로 한 개의 Locker가 여러 명의 멤버를 가질 수 있도록 바뀐다면 ⇒ 위에꺼
주 테이블에 외래 키
•
주 객체가 대상 객체의 참조를 가지고 있는 것 처럼 주 테이블에 외래 키를 두고 대상 테이블을 찾음
•
장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
•
단점: 값이 없으면 외래 키에 null허용
대상 테이블에 외래 키
•
전통적인 데이터베이스 개발자 선호
•
장점: 주 테이블과 대상 테이블을 일대다로 변경할 때 테이블 구조 유지
•
단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨.
다대다
관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
연결 테이블을 추가해서 일대다 다대일 관계로 풀어내야함.
중간 테이블이 등장
다대다 → 1:다 , 다 :1
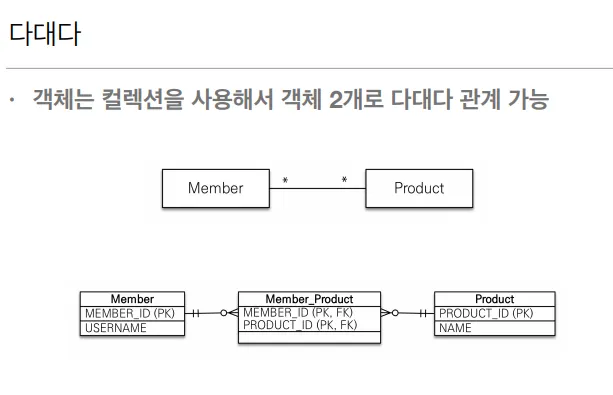
@ManyToMany 사용
@JoinTable로 연결 테이블 지정
다대다 매핑: 단방향 양방향 가능
실무에서 쓰지마라
대신 중간 테이블을 엔티티로 승격시킨다.
@ManyToMany → @ManyToOne, @OneToMany

고급 매핑
상속관계 매핑
관계형 데이터베이스는 상속 관계 X
슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사
상속관계 매핑: 객체의 상속과 DB의 슈퍼타입 서브타입 관계를 매핑
DB입장에서 상속을 3가지로 할 수 있다.
조인전략

Insert는 각각 두 번
Select는 조인해서 들고옴
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn
public class Item{
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A") //-> A로 들간다
public class Album extends Item{
private String artists;
}
@Entity
public class Movie extends Item{
private String Director;
private String Actor;
}
@Entity
public class Book extneds Item{
private String Author;
private String ISBN;
}
Java
복사
장점
•
테이블 정규화
•
외래 키 참조 무결성 제약조건 활용가능, ITEM을 봐야할 때, ITEM_ID만 보면 된다.
•
저장공간 효율
단점 —> 생각보다 단점이 아니다.
•
조회 시 조인을 많이 사용, 성능 저하
•
조회 쿼리가 복잡
•
데이터 저장시 INSERT SQL 2번 호출
단일 테이블 전략

DTYPE을 바탕으로 Album, Movie, Book을 구분
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
//@DiscriminatorColumn, 없어도 DTYPE 생김
public class Item{
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A") //-> A로 들간다
public class Album extends Item{
private String artists;
}
@Entity
public class Movie extends Item{
private String Director;
private String Actor;
}
@Entity
public class Book extneds Item{
private String Author;
private String ISBN;
}
Java
복사
장점
•
조인이 필요 없으므로 조회 성능이 빠름
•
조회 쿼리가 단순
단점
•
자식 엔티티가 매핑한 값들은 전부 null을 허용해야함
•
단일 테이블에 모든 것을 저장하므로, 테이블이 커질 수 있으며, 상황에 따라 성능 저하
구현 클래스마다 테이블 전략
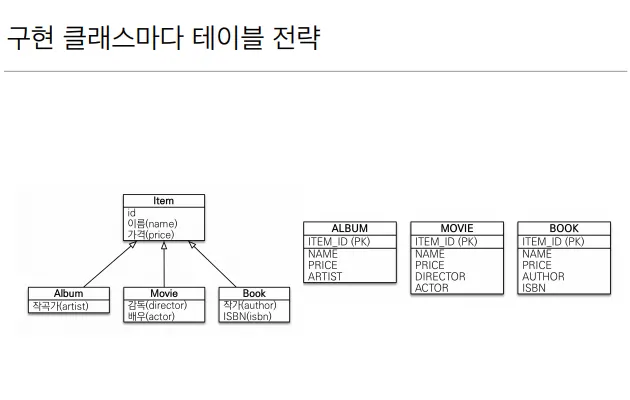
그냥 따로 각각 다 만든다.
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public abstract class Item{ // 추상 클래스로 만드는게 맞다, ITEM이 없기 때문
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
public class Album extends Item{
private String artists;
}
@Entity
public class Movie extends Item{
private String Director;
private String Actor;
}
@Entity
public class Book extneds Item{
private String Author;
private String ISBN;
}
Java
복사
조회할 때, ITEM ID만 알 때, 세 개의 테이블에 전부다 찔러봐야하기 때문에 말이 안된다.
일단 이거는 쓰지말자
매핑 정보 상속 @MappedSuperclass
상속관계 매핑과 별로 관계가 없다.
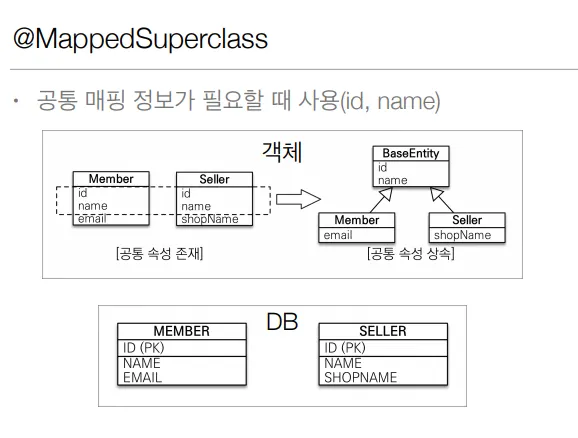
공통적인 속성들을 전부 객체에 집어넣어줘야할 때
매핑정보만 받는 부모클래스를 따로 판다.
상속관계 매핑X
엔티티X, 테이블과 매핑 X
부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
직접 생성해서 사용할 일이 없으므로 추상 클래스로 할 것을 권장
프록시와 연관관계 관리
Member를 조회할 때 Team도 함게 조회해야할까?
Member(String username Team team)
프록시
em.find() vs em.getReference()
em.find(): 데이터베이스를 통해서 실제 엔티티 객체 조회
em.getRefrence(): 데이터베이스 조회를 미루는 가짜 엔티티 객체 조회
→ 가짜로 만든 클래스
실제 데이터를 사용할 때, 쿼리를 날려서 들고온다.
프록시 특징
껍데기는 똑같은데, id만 들고 있는 가짜
실제 클래스를 상속 받아서 만들어짐
실제 클래스와 겉 모양이 같다.
프록시 객체는 실제 객체의 참조(target)을 보관
프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드 호출
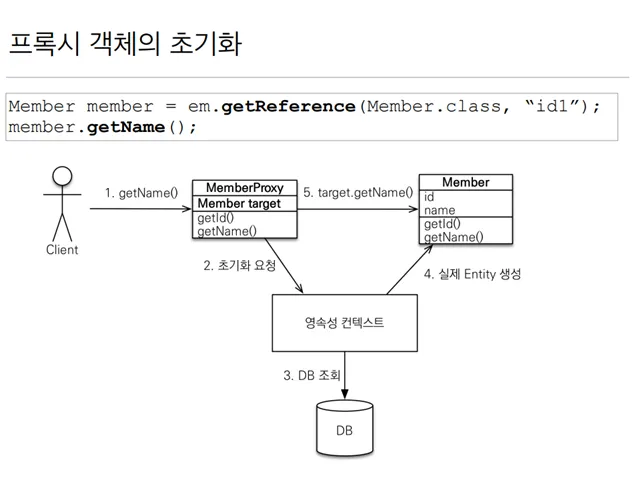
프록시에 값이 없을 때, 영속성 컨텍스트를 통해 초기화를 요청한다.
프록시의 특징
프록시 객체는 처음 사용할 때 한 번만 초기화
프록시 객체를 초기화할 때, 프록시 객체가 실제 엔티티로 바뀌는 것은 아님.
초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능
•
프록시 객체는 원본 엔티티를 상속받음, 따라서 타입 체크시 주의해야함
(==비교 실패, 대신 instance of 사용)
•
영속성 컨텍스트에 찾는 엔티티가 이미 있으면 em.getReference()를 호출해도 실제 엔티티를 반환
→ JPA에서는 한 영속성 컨텍스트에서 같은 걸 들고오면 == 시 true가 나와야함
→ 즉 한 트랜잭션 안에서 컬렉션에서 꺼내온 것과 같이 같은 객체에 대해 true가 나와야한다.
•
거꾸로 프록시로 조회하면 find()하더라도 프록시로 반환한다.
•
영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태일 때, 프록시를 초기화하면 에러
프록시 확인

emf.getPersistenceUnitUtil().isLoaded(Object entity)
즉시 로딩과 지연로딩


JPA 구현체는 가능하면 EAGER를 하려고 함
실무에서는 즉시로딩 주의
가급적 지연로딩만 사용하자
즉시 로딩을 적용하면 예상하지 못한 SQL이 발생
즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
→ JPQL은 일단 SQL로 번역이 된다.
→ 근데 EAGER로 설정되있으니까, Team을 다 조회하는 select문이 10개면 10개 다 나간다.
→ N개만 N개 나가고, 맨 처음에 1개 나감
→ 한 방에 조회할 때는 fetch join하면 됨
OneToMany, ManyToMany는 기본이 지연로딩
ManyToOne은 지연로딩으로 다 해야한다.
지연로딩 활용 - 실무
모든 연관관게에서 지연 로딩을 사용
실무에서 즉시 로딩을 사용하지 마라
JPQL fetch 조인이나 엔티티 그래프 기능을 사용
영속성 전이: CASCADE
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때
Ex)부모 엔티티를 저장할 때 자식 엔티티도 함께 저장


Parent 만 Child를 관리할 때, 소유자가 하나일 때
즉 Child의 주인이 여러 개일 때, 쓰면 안된다.
그래서 게시판이나 첨부파일 경로 같은거 쓸 때
고아 객체
부모 엔티티가 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
orphanRemoval = true;

주의
참조가 제거된 엔티티는 다른 곳에서 참조하지 않는 고아 객체로 보고 삭제하는 기능
참조하는 곳이 하나일 때 사용해야함!
특정 엔티티가 개인 소유할 때 사용
OneToOne, OneToMany만 가능
개념적으로 부모를 제거하면 자식은 고아. 고아 객체 제거 기능을 활성화하면 부모를 제거할 때 자식도 함께 제거됨.
영속성 전이 + 고아 객체, 생명주기
•
CascadeType.ALL + orphanRemoval=true
•
스스로 생병주기를 관리하는 엔티티는 em.persist()로 영속화, em.remove()로 제거
•
두 옵션을 모두 활성화하면 부모 엔티티를 통해서 자식의 생명 주기를 관리할 수 있음
•
도메인 주도 설계의 Aggregate Root개념을 구현할 때 유용
값타입
값타입이란?
엔티티 타입
•
Entity로 정의하는 객체
•
데이터가 변해도 식별자로 지속해서 추적가능
•
회원 엔티티의 키나 나이 값을 변경해도 식별자로 인식 가능
값 타입
•
int, Integer, String
•
식별자가 없고 값만 있으므로 변경시 추적불가
값타입
기본값 타입
•
자바 기본 타입(int, double)
•
래퍼 클래스(Integer, Long)
•
String
생명주기를 엔티티에 의존(회원을 삭제하면 이름,나이 필드도 함께 삭제)
값 타입은 공유하면 X(회원 이름 변경시 다른 회원의 이름도 함께 변경되면 안됨)
기본적으로 자바의 기본타입은 절대 공유X
Integer같은 래퍼 클래스나 String 같은 특수한 클래스는 공유 가능한 객체이지만 변경 X
(변경이 불가하게끔 세팅해놓는다.)
임베디드 타입(embeded Type,복합 값 타입)
새로운 값 타입을 직접 정의할 수 있다.
주로 기본값 타입을 모아서 만들어서 복합 값 타입이라고도 함
int,String 과 같은 값 타입(추적이 안된다.)


장점
•
재사용 가능함
•
높은 응집도
•
Period.isWork()처럼 해당 값 타입만 사용하는 의미 있는 메소드를 만들 수 있다.
•
임베디드 타입을 포함한 모든 값 타입은, 값 타입을 소유한 엔티티에 생명주기를 의존

테이블은 안바뀐다! 매핑만 잘해주면 됨.
임베디드 타입은 엔티티의 값일 뿐
임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다
객체와 테이블을 아주 세밀하게 매핑하는 것이 가능
잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많다
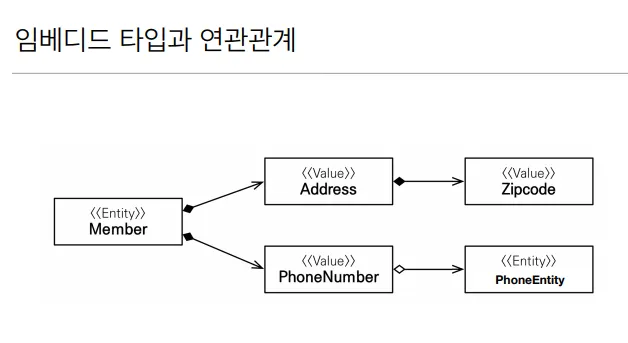
임베디드 타입은 엔티티를 가질 수 있다.
한 엔티티에서 같은 값 타입을 사용하면? → 컬럼 명이 중복됨
AttributeOverrides, AttributeOverride를 사용해서 컬럼 명 속성을 재정의
값 타입과 불변 객체
복잡한 객체 세상을 조금이라도 단순화하려고 만든 개념 → 안전하고 단순하게 다뤄야함.
값 타입 공유 참조?
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험함

대신 값을 복사해서 사용해야한다.
얘네는 레퍼런스 참조를 막을 수가 없다.
불변 객체 → 객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단
값 타입은 불면 객체로 설계해야함
생성자로만 값을 설정하고 수정자로 Setter를 만들지 않으면 됨
값타입은 무조건 불변으로 해라
⇒ 불면이라는 작은 제약으로 부작용이라는 큰 재앙을 막을 수 있다.
바꾸고 싶으면?? 걍 새로 만드셈 ㅋㅋ
값 타입 비교?
인스턴스가 달라도 그 안에 값이 같으면 같은 것으로 봐야함
동일성 비교 : 인스턴스의 참조 값을 비교, ==
동등성 비교: 인스턴스의 값을 비교. equals()
값 타입은? 동등성 비교해야함 ⇒ equals()메소드를 적절히 재정의
값 타입 컬렉션
값 타입을 컬렉션에 담아서 쓰는걸 얘기한다.
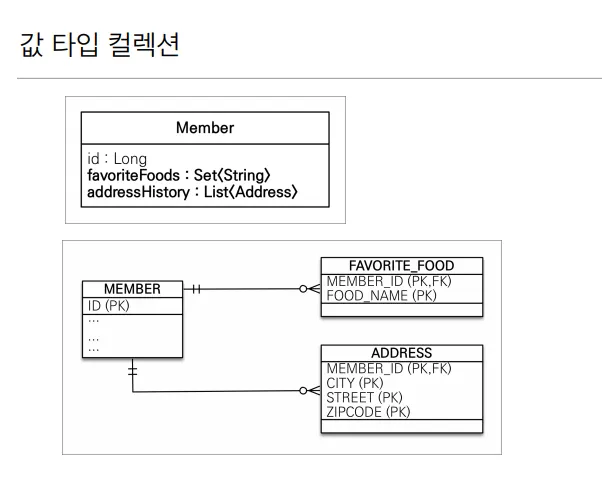

사용
값 타입 저장 → 라이프사이클이 엔티티와 함께 돌아간다.
값 타입 조회 → 값 타입 컬렉션도 지연 로딩 전략 사용
값 타입 수정 → 무조건 새로 갈아끼워야하고, 멤버의 라이프사이클에 다 맞춰진다.
값 타입 삭제 → 객체에 equals를 이용해 비교한다. equals잘못 구현하면 계속 들어감
값 타입 컬렉션은 영속성 전이 + 고아 객체 제거 기능을 필수로 가진다고 볼 수 있다.
제약 사항
값 타입은 엔티티와 다르게 식별자 개념이 없다.
값은 변경하면 추적이 어렵다
값 타입 컬렉션에 변경사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장
값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본 키를 구성해야함: null 입력 X, 중복 저장 X
대안
실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대다 관계를 고려
그냥 엔티티를 만들고 여기에서 값 타입을 사용
언제쓰냐? → 내가 좋아하는 메뉴는 뭐냐? → 추적할 필요도 없고 값이 바뀌어도 업데이트 칠 필요가 없을 때.... 이럴 때 값 타입을 쓴다.
JPQL
JPQL 소개
가장 단순한 조회 방법 → EntityManager.find() , 객체 그래프 탐색
만약에 나이가 18살 이상인 회원을 모두 검색하고 싶다면??
JPQL → 엔티티 객체를 대상으로 검색

Criteria —> 실무에서 안쓴다. 유지보수 불가능
JPQL은 단순한 String → 동적 쿼리를 만들기가 엄청 어렵다.
대안으로 나온게 Criteria

동적 쿼리를 짜기가 쉽다.
JPQL 빌더 역할, 컴파일 타임에 오류를 잡아낼 수 있다.
그래서 대안, QueryDSL
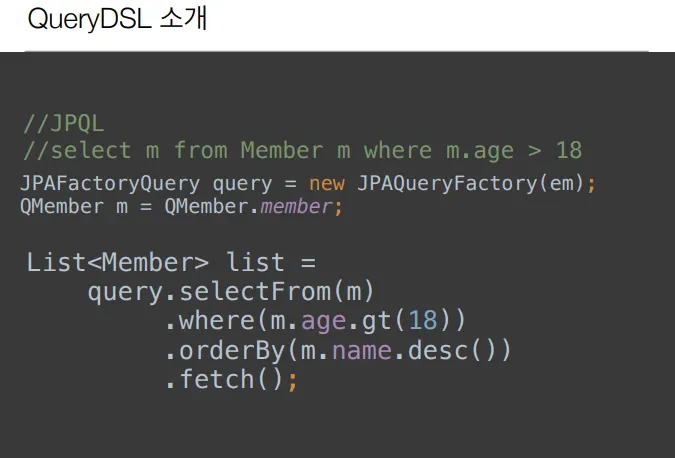
문자가 아닌 자바코드로 JPQL을 작성, JPQL 빌더 역할
컴파일 시점에 문법 오류, 동적쿼리 작성 편리, 단순하고 쉬움
본격 JPQL

select m from Member as m where m.age > 18
엔티티와 속성은 대소문자 구분(Member,age)
JPQL 키워드는 대소문자 구분X(SELECT, FROM, where)
엔티티 이름을 사용, 테이블 이름이 아닌(Member), 별칭은 필수(m)

Group By, Having 도 가능
TypeQuery, Query
TypeQuery: 반환 타입이 명확할 때 사용, Query: 반환 타입이 명확하지 않을 때
TypeQuery
TypeQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class);
Query
Query query = em.createQuery("SELECT m.username, m.age from Member m");
결과 조회 API
query.getResultList(): 결과가 하나 이상일 때, 리스트 반환
→ 결과가 없으면 빈 리스트 반환 : NullPointerException이 안나온다.
query.getSingleResult(): 결과가 정확히 하나
→ 결과가 없으면 NoResultException
→ 둘 이상이면 NonUniqueResultException
파라미터 바인딩
이름 기준이랑 위치 기준이 있다.
<이름>
SELECT m FROM Member m where m.username = :username
query.setParameter("username",usernameParam);
<위치>
SELECT m FROM Member m where m.username = ?1
query.setParameter(1,usernameParam);
프로젝션
SELECT 절에 조회할 대상을 지정하는 것
프로젝션 대상: 엔티티, 임베디드 타입, 스칼라 타입 등등

엔티티 프로젝션 → 결과들이 영속성 컨텍스트에 다 관리됨
여러 필드를 들고와야할 때, 어떻게 해야하지??
1.
Query 타입으로 조회
List resultList = em.createQuery("select m.username, m.age from Member m").getResultList();
여기에는 Object[]이 들어가있다.
Object o = resultList.get(0);
Object[] result = (Object[]) o;
2.
제네릭에 Object[]으로 그냥 조회해라
List<Object[]> resultList = em.createQuery("select m.username, m.age from Member m").getResultList();
3.
제일 깔끔한 new 명령어로 조회
단순한 값을 DTO로 바로 조회
생성자 호출하듯이 하면 됨
select new jpabook.jpql.UserDTO(m.username, m.age) from Member m
페이징 API
JPA는 페이징을 다음 두 API로 추상화
setFirstResult(int startPosition): 조회 시작 위치
setMaxResults(int maxResult): 조회할 데이터 수
List<Member> resultList = em.createQuery(jpql, Member.class).setFirstResult(10).setMaxResults(20).getResultList();
조인
내부 조인:
외부 조인:
세타 조인:
select count(m) from Member m, Team t where m.username = t.name


서브 쿼리
select m from Member m
where m.age >(select avg(m2.age) from Member m2)
select m from Member m where(select count(o) from Order o where m=o.member) >0
[NOT] EXISTS: 서브 쿼리에 결과가 존재하면 참
ALL : 모두 만족하면 참
ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참
[NOT] IN: 서브 쿼리 결과 중 하나라도 같은 것이 있으면 참

JPQL의 타입 표현
문자 : 'HELOO','She''s'
숫자: 10L 10D, 10F
boolean: TRUE,FALSe
ENUM: jpabook.MemberType.Admin
엔티티 타입: TYPE(m) = Member → DTYPE 챙겨주기
조건식
CASE식
•
기본 CASE 식
SELECT case when m.age ≤ 10 then '학생요금'
when m.age ≥ 60 then '경로 요금'
else '일반 요금'
end
from Member m
•
단순 CASE 식
select
case t.name
when '팀A' then '인센티브110%'
when '팀B' then '인센티브120%'
else '인센티브105%'
end
from Team t
•
COALESCE
하나씩 조회해서 null이 아니면 반환
select Coalesce(m.username, '이름 업슨 회원') from Member m
•
NULLIF
두 값이 같으면 null 반환, 다르면 첫번째 값 반환
select NULLIF(m.username,'관리자') from Member m
사용자 정의 함수 호출
JPQL은 기본 함수가 있다
CONCAT, SBSTRING, TRIM, LOWER, UPPER, LENGTH, LOCAT, ABS, SQRT, MOD, SIZE, INDEX
짜여져있는 함수를 써도 되고, 내가 만든 함수를 등록할 수도 있다.
select function('group_concat', i.name) from Item i
이런 식으로
중급 문법
경로 표현식
•
점을 찍어 객체 그래프를 탐색하는 것
m.username → 상태필드
m.team → 단일 값 연관 필드
m.orders → 컬렉션 값 연관 필드
상태필드: 단순히 값을 저장하기 위한 필드
연관 필드: 연관관계를 위한 필드
Ex) 단일값 연관 필드, 컬렉션 값 연관 필드
단일값 연관 필드 → 대상이 엔티티, ManyToOne, OneToOne
컬렉션 값 연관 필드 → 대상이 컬렉션, OneToMany, ManyToMany
상태필드: 경로 탐색의 끝, 탐색X
단일 값 연관 경로: 묵시적 내부 조인(inner join)발생, 탐색 O
컬렉션 값 연관 경로: 묵시적 내부 조인 발생, 탐색 X, FROM 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
명시적 조인, 묵시적 조인
명시적 조인: join키워드 직접 사용
묵시적 조인: 경로 표현식에 의해 묵시적으로 SQL 조인 발생
•
가급적 묵시적 조인 대신 명시적 조인
•
조인은 SQL 튜닝에 중요 포인트
•
묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어려움
Fetch Join
실무에서 정말정말 중요함
SQL 조인 종류 X
JPQL에서 성능 최적화를 위해 제공하는 기능
연관된 엔티티나 컬렉션을 SQL 한번에 함께 조회하는 기능
join fetch 명령어 사용
Ex) select m from Member m join fetch m.team
—> SELECT M.* T.* FROM MEMBER M INNER JOIN TEAM T ON M.TEAM_ID = T.ID
컬렉션 페치 조인
일대다 관계에서 사용


SQL의 DISTINCT는 중복된 결과를 제거하는 명령
JPQL → DISTINCT : SQL에 DISTINCT를 추가하고, 엔티티에서 엔티티 중복 제거
페치 조인 vs 일반 조인
JPQL은 결과를 반환할 때 연관관계 고려 X, 단지 SELECT 절에 지정한 엔티티만 조회
페치 조인을 사용할 때만 연관된 엔티티도 함께 조회
페치 조인은 객체 그래프를 SQL한번에 조회하는 개념
페치 조인의 특징과 한계
•
페치 조인 대상에는 별칭을 줄 수 없다.
하이버네이트는 가능, 가급적 사용 X
•
둘 이상의 컬렉션은 페치 조인 할 수 없다.
•
컬렉션을 페치 조인하면 페이징API를 사용할 수 없다.
일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험)
결론
•
모든 것을 페치 조인으로 해결할 수는 없음
•
페치 조인은 객체 그래프를 유지할 때 사용하면 효과적
•
여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야하면, 페치 조인보다는 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적
다형성 쿼리
조회 대상을 특정 자식으로 한정
Ex) Item 중에 Book, Movie 를 조회해라
•
JPQL
select i from Item i where type(i) IN (Book, Movie)
•
SQL
select i from i where i.DTYPE in ('B','M')
TREAT
•
자바의 타입 캐스팅과 유사
•
상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때
•
FROM, WHERE, SELECT 사용
•
JPQL
select i from Item i where treat(i as Book).author = 'kim'
•
SQL
엔티티 직접 사용
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
Ex) select count(m) from Member m
= select count(m.id) from Member m
→ select count(m.id) as cnt from Member m


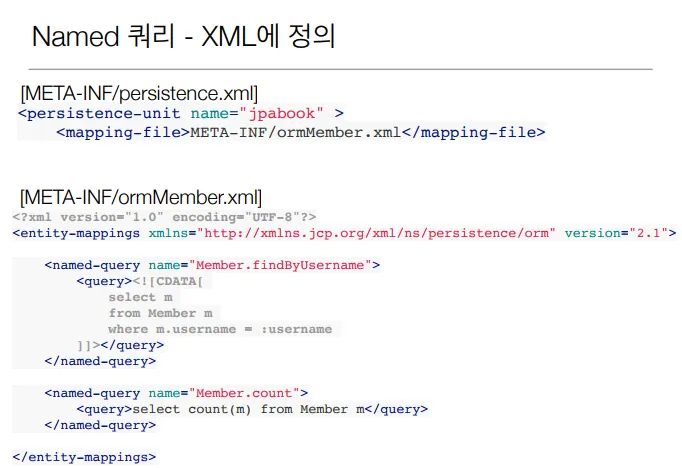
Named 쿼리
미리 정의해서 이름을 부여해두고 사용하는 JPQL
정적 쿼리
어노테이션, XML에 정의
애플리케이션 로딩 시점에 초기화 후 재사용
애플리케이션 로딩 시점에 쿼리를 검증
@Entity
@NamedQueyr(
name = "Member.findByUsername", queyr = "select m from Member m where m.username = :username")
public class Member{
}
List<Member> resultList = em.createNamedQuery("Member.findByUsername",Member.class)
.setParameter("username","회원1")
.getResultLlist();
Java
복사
XML이 항상 우선권을 가짐
벌크 연산
JPA 변경 감지 기능으로 실행하려면 너무 많은 SQL 실행
Ex) 재고가 10개 미만인 상품을 리스트로 조회
상품 엔티티의 가격을 10%증가
트랜잭션 커밋 시점에 변경 감지가 동작, 데이터가 100건이라면 100번의 update sql실행
•
쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
•
executeUpdate()의 결과는 영향 받은 엔티티 수 반환
•
update, delete 지원
•
insert(insert into...select, 하이버네이트 지원)
String sqlString = "update Product p" + "set p.price = p.price *1.1 " + "where p.stockAmount < : stockAmount";
int resultCount = em.createQuery(sqlString).setParameter("stockAmount", 10).executeUpdate();
벌크 연산 주의
•
영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리
•
벌크 연산을 먼저 실행 or 벌크 연산 수행 후 영속성 컨텍스트 초기화