
JVM 이해하기

JVM
•
자바 가상 머신으로 자바 바이트 코드를 OS에 특화된 코드로 변환(인터프리터와 JIT컴파일러)하여 실행한다.
•
바이트 코드를 실행하는 표준이자 구현체
•
JVM 스펙, JVM벤더(오라클, 아마존, Azul)
•
특정 플랫폼에 종속적: Native 코드에 맞춰서 실행해야하기 때문에
JRE
•
자바 애플리케이션을 실행할 수 있도록 구성된 배포판
•
JVM과 핵심 라이브러리 및 자바 런타임 환경에서 사용하는 프로퍼티 세팅이나 리소스 파일을 가지고 있다.
•
개발 관련 도구는 제공하지 않음. (실행은 할 수 있다. 단, 컴파일할 때 썼던 javac같은 거는 못 씀)
JDK
•
JRE + 개발에 필요한 툴
•
소스 코드를 작성할 때 사용하는 자바 언어는 플랫폼에 독립적
•
오라클은 자바 11부터 JDK 만 제공하며, JRE를 따로 제공하지 않는다.
JAVA
•
프로그래밍 언어
•
JDK에 들어있는 자바 컴파일러를 사용하여 바이트코드(.class파일) 로 컴파일 할 수 있다.
•
자바 유료화? 오라클에서 만든 Oracle JDK 11버전부터 상용으로 사용할 때 유료
◦
오라클에서 만든 Oracle Open JDK라고 있다. 이거는 무료
◦
오라클에서 만들지 않은 Open JDK
타 프로그래밍 언어 지원
•
JVM 기반으로 동작
•
클로져, 그루비, 루비, 코틀린 등
JVM 이해하기
1.
클래스 로더 시스템
2.
메모리
3.
실행엔진
4.
JNI, 네이티브 메소드 라이브러리
클래스 로더 시스템
바이트 코드를 읽어들여서 메모리에 적절히 올려놓는 것
로딩: 바이트 코드를 읽어오는 것
링크: 레퍼런스를 연결하는 과정
초기화: static한 값들을 초기화한다.
메모리
영역: 스택, PC, 네이티브 메소드 스택, 힙, 메소드
메소드 영역: 클래스 수준의 정보( 클래스 이름, 부모 클래스 이름, 메소드, 변수) 저장, 고유 자원(다른 영역에서 참조할 수 있는 거다)
힙 영역: 객체를 저장(인스턴트들을 저장). 공유 자원
쓰레드 단위로 공유되는 자원
스택 영역: 쓰레드마다 런타임 스택을 만들고, 그 안에 메소드 호출을 스택 프레임이라 부르는 블럭으로 쌓는다.(메소드 콜), 쓰레드 종료하면 런타임 스택도 사라진다.
PC(Program Counter) 레지스터: 쓰레드마다 쓰레드 내 현재 실행할 스택 프레임을 가리키는 포인터가 생성된다.
네이티브 메소드 스택: 네이티브 메소드가 쌓이는 스택:
(네이티브 메소드라 하믄?, 네이티브라는 키워드가 있고, C나 C++로 구현되어있는 것)
실행엔진
바이트 코드들을 이해할 수 있다.
한줄 한줄씩 실행하면서 네이티브 코드로 바꿔서 이해하면서 실행하는 것
네이티브 언어로 한줄씩 컴파일하는 것
JIT 컴파일러: 인터프리터 효율을 높이기 위해, 인터프리터가 반복되는 코드를 발견하면 JIT 컴파일러로 반복되는 코드를 모두 네이티브 코드로 바궈둔다. 그 다음부터 인터프리터는 네이티브 코드로 컴파일된 코드를 바로 사용
GC(Garbage Collector): 더이상 참조되지 않는 객체를 모아서 정리
•
Stop-The-World : 많은 객체를 생성하고 응답 시간이 중요하다
•
Throw-put:
클래스 로더 시스템
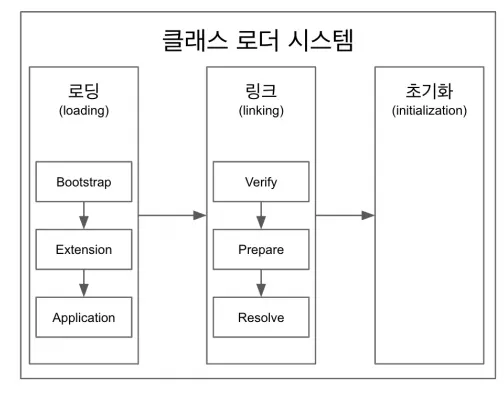
로딩
•
클래스 로더가 .class 파일을 읽고 그 내용에 따라 적절한 바이너리 데이터를 만들고 "메소드" 영역에 저장
•
이 때 메소드 영역에 저장하는 데이터
◦
FQCN(Full Qualified Class Name)
◦
클래스 , 인터페이스, Enum
◦
메소드와 변수
•
로딩이 끝나면 해당 클래스 타입의 class객체를 생성하여 '힙'영역에 저장
계층 구조로 이뤄져있다
부트스트랩 클래스 로더 → 플랫폼 클래스로더 → 애플리케이션 클래스로더
부트스트랩: JAVA_HOME\lib에 있는 코어 자바 API를 제공, 최상위 우선순위
플랫폼 클래스로더 : JAVA_HOME\lib\ext 폴더 또는 java.ext.dirs 시스템 변수에 해당하는 위치에 있는 클래스를 읽는다
애플리케이션 클래스로더: 애플리케이션 클래스패스에서 클래스를 읽는다.
링크
Verify → Prepare → Resolve(optional)
Verify: .class파일 형식이 유효한지 체크
Preparation: 클래스 변수와 기본값에 필요한 메모리
Resolve: 심볼릭 메모리 레퍼런스를 메소드 영역에 있는 실제 레퍼런스로 교체
심볼릭 메모리 레퍼런스: 논리적인 레퍼런스다. 실제 Heap에 있는 레퍼런스로 가리키게끔 하는게 Resolve
초기화
static 변수의 값을 할당한다.
바이트 코드 조작
코드 커버리지는 어떻게 측정할까?
코드 커버리지 → 테스트 코드가 확인한 소스 코드를 %로 나타내준다.
코드 커버리지 툴의 동작 원리
•
바이트 코드를 읽어서 코드 커버리지를 챙겨야하는 부분을 개수를 샌다.
•
코드가 실행될 때, 어디가 실행됬는지 비교하는 거다.
노란색: 완벽하게 지나간게 아니다. if문의 분기를 다 지나간게 아니다
초록색: 지나간 부분
빨간색: 아예 지나가지 않은 부분
모자에서 토끼를 꺼내는 마술
public class Moja{
public String pullOut(){
return "";
}
}
Java
복사
public class Masulsa{
public static void main(String[]args){
System.out.println(new Moja().pullOut());
}
}
Java
복사
bytebuddy → 클래스가 바이트 코드로 변경될 때, 바이트코드를 조작하는 것이다.
javaagent → 클래스 로더가 클래스를 읽어올 대 javaagent를 거쳐서 변경된 바이트코드를 읽어들여 사용한다.
바이트 코드 활용 예
1.
프로파일러: 메모리를 얼마나 쓰는지, 쓰레드는 얼마나 쓰는지 등등, 성능 분석 툴
2.
최적화, 로깅 등등
3.
프록시 객체를 만드는데도 쓰인다.
Ex) 스프링이 컴포넌트 스캔을 하는 방법(asm)
컴포넌트 스캔으로 빈으로 등록할 후보 클래스 정보를 찾는데 사용
특정한 애노테이션 정보가 붙어있는 클래스들을 찾는 과정
ClassPathScanningCandidateComponentProvider → SimpleMetadataReader
ClassReader와 Visitor를 사용해서 클래스나 메소드에 있는 애노테이션 정보를 들고온다.
코드를 분석하는데 쓰는 것!
리플렉션
리플렉션 API 1부: 클래스 정보 조회
Class<Book> bookClass = Book.class;
Book book = new Book();
Class<? extends Book> aClass = book.getClass();
Class<?> aClass1 = Class.forName("me.whiteship.Book");
Java
복사
모든 클래스를 로딩 한 다음 Class의 인스턴스가 생긴다.
•
“타입.class”로 접근할 수있다.
•
모든 인스턴스는 getClass() 메소드를 가지고 있다. “인스턴스.getClass()”로 접근할 수
있다.
•
클래스를 문자열로 읽어오는 방법
◦
Class.forName(“FQCN”)
◦
클래스패스에 해당 클래스가 없다면 ClassNotFoundException이 발생한다.
class<T>를 통해 할 수 있는 것
•
필드 가져오기
•
메소드 가져오기
•
상위 클래스 가져오기
•
인터페이스 가져오기
•
애노테이션 가져오기
•
생성자 가져오기
애노테이션과 리플렉션
애노테이션은 근본적으로 주석과 같은 정보다
소스에서도 남고, 클래스에서도 남는데, byte Code를 로딩했을 때 메모리에서는 남지 않는다.
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.Type, ElementType.FIELD}) // 애노테이션을 어디에 쓸 수 있는지
@Inherited // 상속 관계에서 애노테이션이 상속된다.
public @interface myAnnotation(){
String name() default "keesun";
int number() default 100;
}
Java
복사
이런 식으로 애노테이션을 정의해야 메모리에도 애노테이션 정보가 남는다.
Arrays.stream(Book.class.getAnnotations()).forEach(System.out::println);
Java
복사
이런 식으로 애노테이션을 확인할 수 있다.
클래스 정보 수정 또는 실행
public class Book{
public static String A = "A";
private STring B = "B";
public Book(){
}
private void c(){
System.out.println("C");
}
public int sum(int left, int right){
return left * right;
}
}
Java
복사
public class App{
public static void main(String[] args] throws classNotFoundException{
Class<?> bookClass = class.forName("me.whiteship.Book");
Constructor<?> constructor = bookClass.getConstructor(String.class);
Book book = (Book) constructor.newInstance("myBook");
System.out.println(book);
Field a = Book.class.getDeclaredField("A");
a.get(null);
a.set(null,"AAAA");
Field b = Book.class.getDeclaredField("B");
b.setAccessible(true);
b.get(book);
b.set(book,"BBBB");
}
}
Java
복사
나만의 DI 프레임워크 만들기
리플렉션을 사용해서, 클래스 정보를 받아오고, 인스턴스를 만드는 방식으로 사용할 수 있다.
리플렉션 정리 및 활용
스프링
•
의존성 주입
•
MVC 뷰에서 넘어온 데이터를 객체에 바인딩
하이버네이트
•
@Entity 클래스에 Setter가 없다면 리플렉션을 사용
주의할점!
컴파일 타임에 확인되지 않고 런타임 시에만 발생하는 문제를 만들 가능성이 있다.
접근 지시자를 무시할 수 있다.
지나친 사용은 성능 이슈를 야기할 수 있다. 반드시 필요한 경우에만 사용할 것
다이나믹 프록시
스프링 데이터 JPA는 어떻게 동작하나?
public interface BookRepository extends JpaRepository<Book,Integer>{
}
//???? 어떻게 이게 인터페이슨데, 인터페이스 인스턴스가 만들어졌냐?
//사용시 이렇게 사용한다.
@Auowired BookRepository bookRepository;
Java
복사
인터페이스에 정의만 되어있는 애들인데 어떻게 동작을 하냐?
누가 어떻게 구현을 해서 객체를 만드는가? —> 프록시라는 클래스
데이터 JPA는 AOP코드를 쓰고 있다.
AOP → ProxyFactory를 제공한다.
프록시 패턴
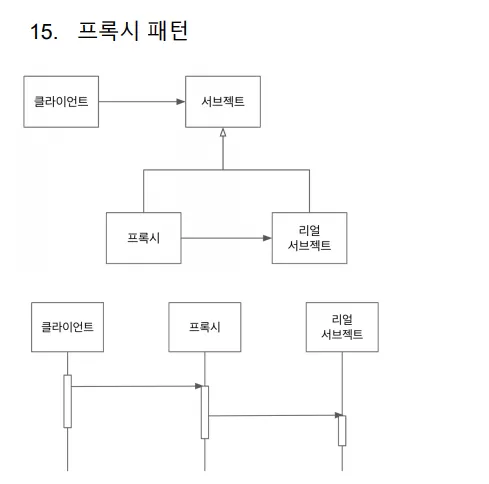
프록시도 리얼서브젝트도 같은 인터페이스를 구현하고 있다.
프록시는 리얼 서브젝트를 참조하고 있다.
클라이언트는 프록시를 사용함.
•
프록시와 리얼 서브젝트가 공유하는 인터페이스가 있고, 클라이언트는 해당 인터페이스 타입으로 프록시를 사용한다
•
클라이언트는 프록시를 거쳐서 리얼 서브젝트를 사용하기 때문에 프록시는 리얼 서브젝트에 대한 접근을 관리하거나 부가기능을 제공하거나 리턴값을 변경할 수도 있다.
•
리얼 서브젝트는 자신이 해야할 일만 하면서(SRP) 프록시를 사용해서 부가적인 기능(접근 제한, 로깅, 트랜잭션 등)을 제공할 때 이런 패턴을 주로 사용함.
public class BookServiceProxy implement BookService{
BookService bookService;
public BookServiceProxy(BookService bookService){
this.bookService = bookService;
}
@Override
public void rent(Book book){
System.out.println("aaaaa");
bookService.rent(book);
}
@Override
public void returnBook(Book book){
System.out.println("aaaa");
bookService.returnBook(book);
}
}
//프록시 패턴으로 할 때 비슷한 기능들이 계속 생겨난다.
// 이런 것들을 클래스로 정의해놓는게 아니라, 런타임에 특정 인터페이스들을 구현하는
// 클래스 또는 인스턴스를 만드는 기술
Java
복사
다이나믹 프록시
런타임에 특정 인터페이스들을 구현하는 클래스 또는 인스턴스를 만드는 기술
public class BookServiceTeset{
BookService bookService = (BookSerivce) Proxy.newProxyInstance(BookService.class.getClassLoader(),
new Class[]{BookService.class},
new InvocationHandler(){
BookService bookService = new DefaultBookService();
@Override
public Object invoke(Object proxy, Method method, Object[]args) throws Throwable{
if(method.getName().equals("rent")){
System.out.println("aaaa");
Object invoke = method.invoke(bookService,args);
System.out.println("bbbb");
return invoke;
}
return method.invoke(bookSerivce,args);
}
});
Java
복사
코드가 너무 더럽다...
스프링 AOP → 프록시 기반의 AOP
이건 자바가 제공하는 프록시 기술
다이나믹 프록시 → 클래스 기반의 프록시를 만들어주지 못한다.
클래스의 프록시가 필요하다면?
서브 클래스를 만들 수 있는 라이브러리를 사용하여 프록시를 만들 수 있다.
CGlib
MethodInterceptor handler = new MethodInterceptor(){
BookService bookService = new BookService();
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
System.out.println("aaa");
Object invoke = method.invoke(bookSerivce,args);
System.out.println("bbb");
return invoke;
}
}
BookService bookService = (BookSerivce) Enhancer.create(BookService.class, handler)
Java
복사
ByteBuddy —> 너무 어려운데..?하핳..
서브 클래스를 만드는 방법의 단점
•
상속을 사용하지 못하는 경우 프록시를 만들 수 없다.
◦
private한 생성자만 있는 경우
◦
final 클래스인 경우
•
인터페이스가 있을 때는 인터페이스의 프록시를 만들어 사용할 것.
사용처
스프링 데이터 JPA
스프링 AOP
Mockito
하이버네이트 lazy initialization
??? 지금까지는 바이트코드를 조작, 바이트 코드 이전에는 조작할 수 없는가?, 소스코드 레벨에서 컴파일에서 또 다른 소스코드를 생성해낼 수 있는 기능 → Lombok
애노테이션 프로세서
롬복은 어떻게 동작할까?
애노테이션 프로세서 → 애노테이션이 붙어있는 소스코드가 컴파일 될 때 또 다른 소스코드를 만들어낸다.
•
소스코드의 AST(abstract syntax tree) 를 조작한다.
•
공개된 API가 아닌 컴파일러 내부 클래스를 사용하여 기존 소스 코드를 조작한다.
애노테이션 프로세서
사용 예
•
롬복
•
AutoService: java.util.ServiceLoader 용 파일 생성 유틸리티 → 리소스 파일을 생성
•
@Override
런타임 비용이 제로 but 기존 클래스 코드를 변경할 때는 약간의 hack이 필요하다