문제점
•
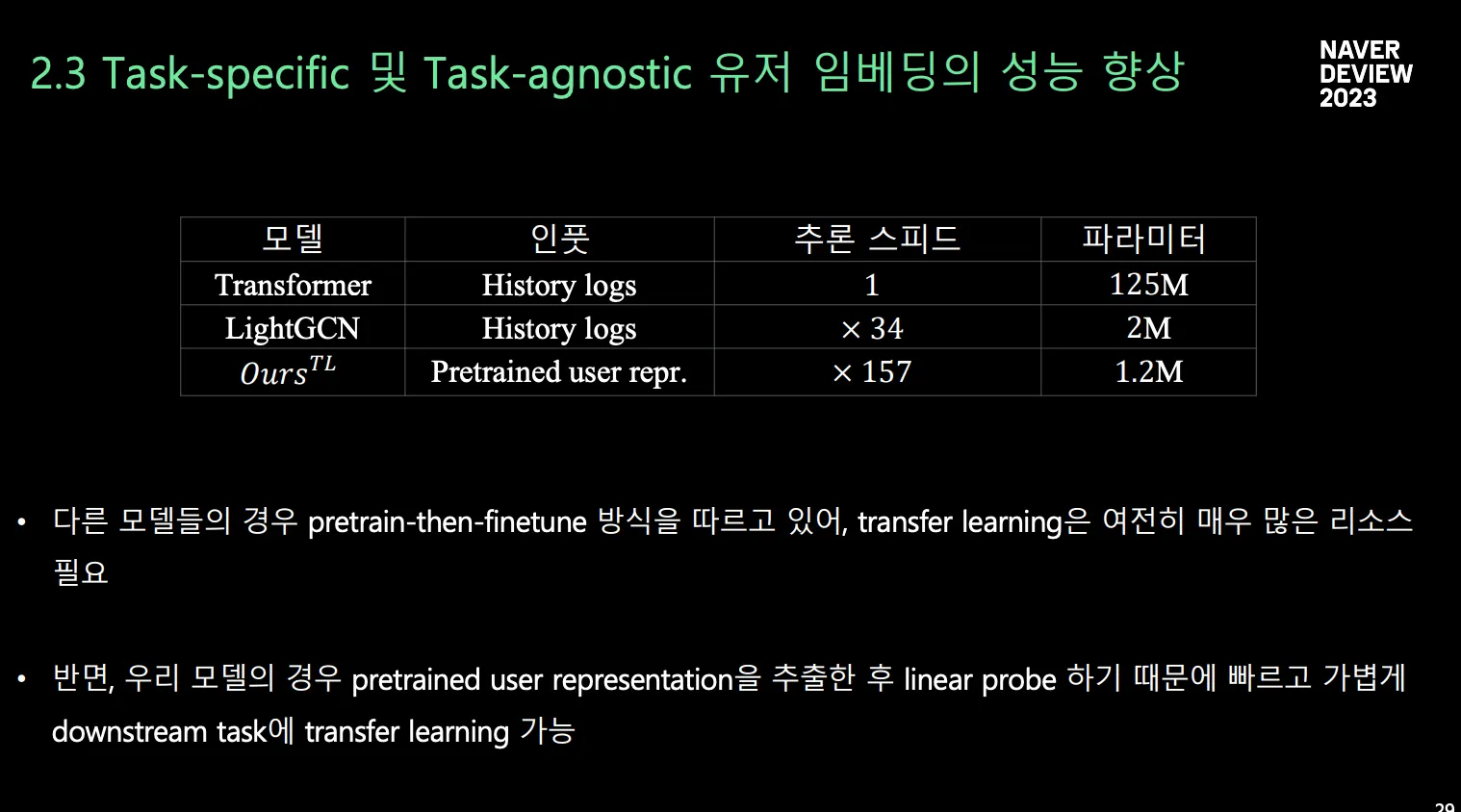
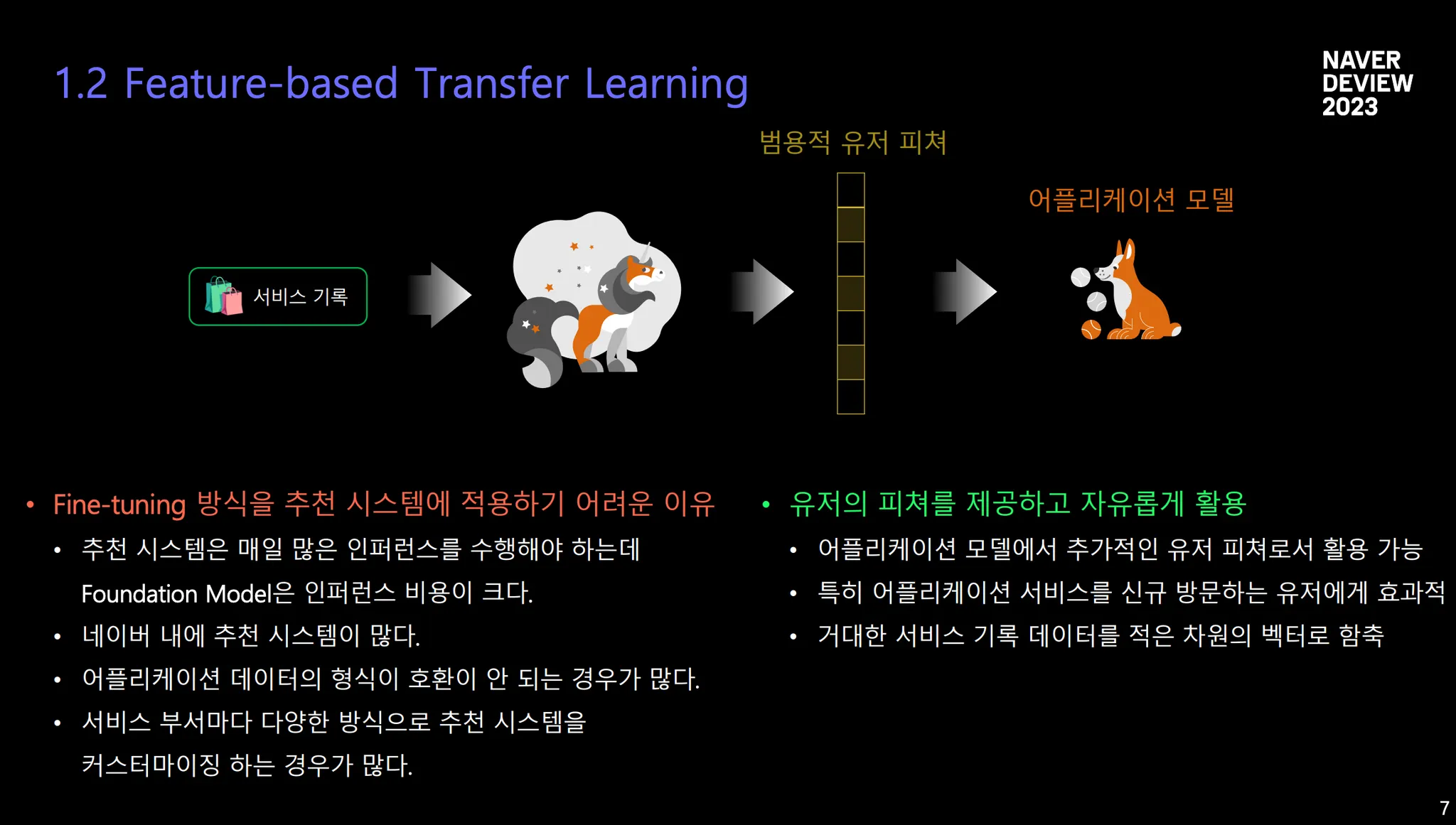
인퍼런스 Cost 증가 ⇒ Fine-tuning 방식이 힘듦
•
범용적인 유저 피쳐를 만듦으로써 downstream task에도 사용가능하도록
언어 모델을 활용한 기존 유저 모델링 연구
U-BERT → P5 → Clue → M6-Rec → Universal Sequential User Representation(Alibaba)
•
U-BERT
◦
언어 모델 Objective + fine-tuning 방식
◦
Pretext Task: 리뷰에서 사용자의 선호도를 나타내는 단어 맞추기 & 리뷰 점수 예측
◦
Downstream Tasks: Recommendation Tasks finetuning
•
P5
◦
Text-to-Text Recommendation
◦
Pretext Task: Prompt engineering을 통해 user modeling tasks
◦
Downstream Tasks: 다양한 추천 시스템 task + zero-shot task
•
Clue
◦
Pretrain 모델 사이즈의 추천 task 능력에 대한 Scaling Law를 탐구
•
M6-Rec
◦
대규모 언어 모델을 이용한 end-to-end 방식의 추천
◦
Pretext Task: User Modeling w/ 자연어
◦
Downstream task: 여러 추천 시스템 Task
•
Alibaba
◦
transfer learning에 초점을 맞춘 sequential recommendation framework 제안
언어 모델링이 분류 학습에 도움이 된다!
•
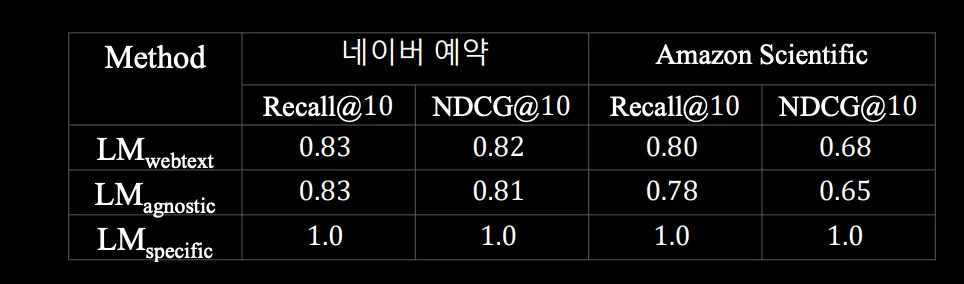
web text 기반이 아닌 task-specific 데이터 + task agnostic data를 활용한 언어 모델이 우수할 수 있음
•
language model pretraining이 downstream task를 푸는데 도움이 되는 objective이다
•
실험 결과
◦
데이터 양이 매우 적음에도 성능이 비슷하다.
Terminology
•
Task-specific data: Target downstream task의 user history logs data
•
Task-agnostic data는 target downstream이 아닌 다른 History log
Modeling
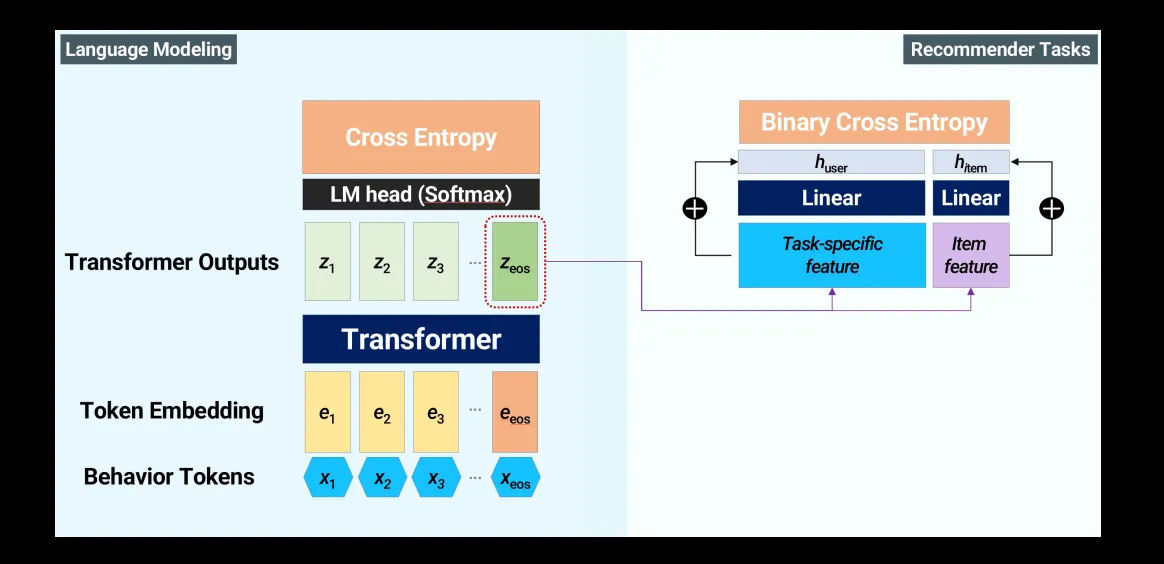
•
catastrophic forgetting을 피하기 위해 multi-task modeling을 시도함.
•
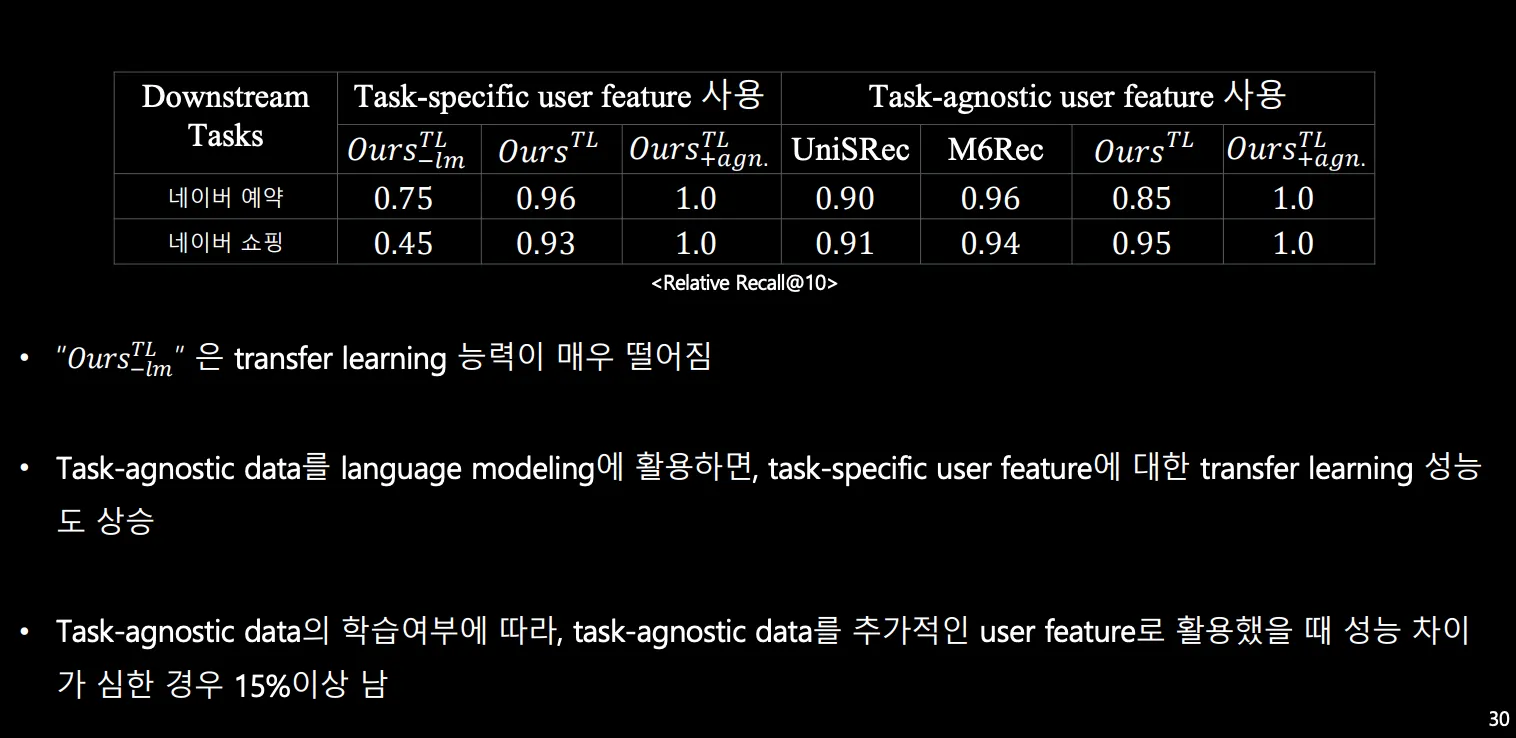
Task-agnostic data를 사용하면 성능이 향상된다!
◦
특정한 language corpus에 overfitting하는 것을 방지한다.
Transfer Learning
A: target downstream task
B: pretraining task-specific task data
C: pretraining task-agnostic task data
B,C로 학습한 트랜스포머의 파라미터를 frozen을 해놓고, A 데이터에 대해 user/item feature를 뽑고 성능 평가 진행
user-ID로 로그를 매칭시킬 수 있다면 C에서 로그를 가져와서, C의 임베딩을 뽑아서, A,C의 임베딩을 A의 Task를 optimization 하는데 사용할 수 있다. → C의 임베딩을 뽑고, A와 C에 대해서 linear probe optimization을 진행함.