
Abstract
•
LLM을 이용한 추천 시스템이 좋은 점
◦
LLM
▪
자기 지도 학습을 통해 대량의 데이터를 학습으로 보편적인 representation이 좋다.
▪
미세 조정 및 프롬프트 튜닝 등의 효과적인 전달 기술
◦
고픔질 텍스트 특성의 표현 및 아이템과 사용자 사이의 관계를 맺어주는 외부 지식들의 활용
•
LLM 추천에 대해 두 가지로 나눠서 봄
◦
Discriminative LLM
◦
Generative LLM
•
해당 패러다임에 대해서 분석/도전과제/인사이트를 발견
Introduction
•
LLM을 추천시스템에 결합하면 가장 큰 이점
◦
텍스트 피쳐에 대한 high-quality 표현을 추출할 수 있다.
◦
인코딩된 방대한 외부지식을 활용할 수 있다.
•
LLM은 self/semi-supervised learning을 이용한 모델을 기본적으로 말한다.
•
LLM기반 추천 모델은 문맥 정보 / 사용자 쿼리 / 아이템 설명 / 텍스트 데이터를 더 잘 이해함.
•
제한된 historical interaction 데이터 희박성 문제에 직면해서 LLM은 zero/few-shot 추천 capabilities 를 통해 돌파했다.
◦
Discriminative의 fine-tuning 문제를 few-shot으로 해결해낸 Generative LLm
•
특정한 아이템이나 사용자에 대한 노출 없이도 방대한 사전 훈련(사실 기반 정보, 도메인 지식, 상식 추론 등)을 통해 합리적인 추천이 가능함.
◦
이건 discriminative 모델에 이미 사용 중임
•
생성 언어 모델이 주목 받기 시작하면서, 생성 모델과 추천 시스템의 결합이 더욱 기대됨.
◦
LLM 기반 시스템의 언어 생성 능력을 바탕으로 추천에 영향을 끼치는 요인을 이해하는데 도움을 준다.
◦
생성 모델은 개인화되고 context-aware한 추천을 해줌. 대화 베이스의 추천 시스템을 통해
•
LLM 활용 추천시스템
◦
Zeng et al, Liu et al. Zeng et al
◦
Zeng et al
▪
추천 모델의 사전 훈련을 요약하고 다른 도메인 간의 지식 전달 방법
◦
Liu et al
▪
직교 분류 체계를 통해 사전 훈련 언어 모델 기반 추천 시스템을 분류.
▪
사전훈련 언어모델 기반의 추천 시스템과 다른 인풋 데이터 타입 간의 연결성을 분석 및 요약 (??)
◦
이런 연구는 어떻게 전달할지에 포커스를 맞추지, 언어 모델의 잠재력과 능력을 탐색하지는 않는다.
◦
추천 시스템에서 생성형 LLM에 대한 체계적인 소개와 최근 진보가 어떻는지가 없다.
▪
Discriminative LLM과 생성형 LLM으로 나누며 후자에 초점을 맞춘다.
▪
추천 시스템을 위한 생성형 LLM에 대한 최신이자 포괄적인 리뷰를 하는 첫 작업임
▪
작업 요약
•
LLM 기반 추천 시스템의 상태에 대한 체계적인 조사 제시, 언어 모델의 capacity 확장에 초점을 맞춤. 존재하는 방법들을 분석함으로써, 관련된 발전과 적용에 대한 체계적인 개요 제시함.
•
모델링 패러다임 관점에서, LLM 추천 모델의 현재 연구를 세 가지 사고 학파로 분류함
•
장점, 단점, 한계를 비판적으로 분석. LLM 기반 추천 시스템이 직면한 주요 도전 과제 및 인사이트를 제공
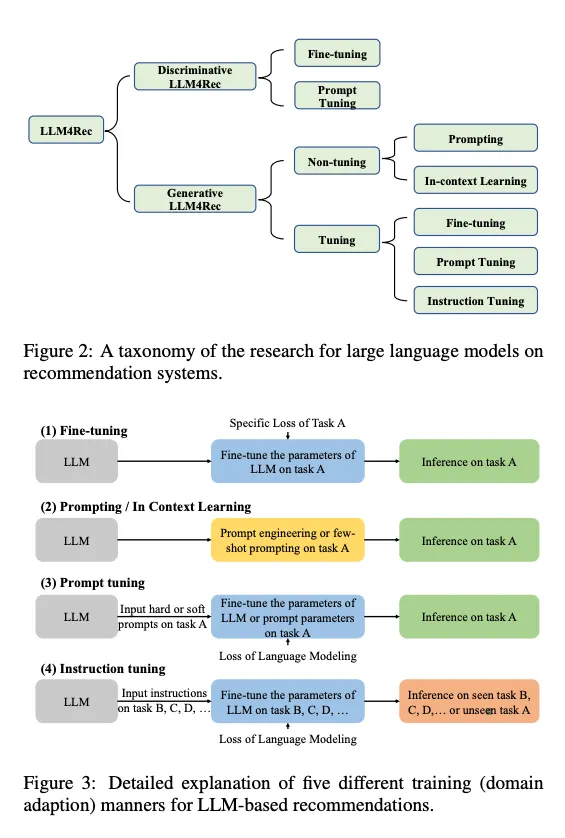
Modeling 패러다임 및 분류
세 가지 분류로 나눌 수 있다.
1.
LLM 임베딩 + RS
a.
언어 모델을 특성 추출기로 바라본다.
b.
아이템과 사용자의 특성을 LLM에 입력하여 해당 임베딩을 출력
c.
전통적인 RS 모델은 이걸 다양하게 활용 가능함.
2.
LLM 토큰 + RS
a.
입력으로 들어간 아이템과 사용자의 특성을 기반으로 토큰을 생성
b.
생성된 토큰은 semantic mining을 통해 잠재적인 선호도를 포착한다.
c.
이건 추천 시스템의 decision making process와 결합될 수 있음
3.
LLM을 RS로 사용
a.
1,2랑 다르게 이건 사전 학습된 LLM을 강력한 추천 시스템으로 직접 전환하는 것을 목표로 함.
b.
입력 시퀀스는 프로필, 행동 프롬프트, 작업 지시로 구성됨. 아웃풋 시퀀스는 합리적인 추천 결과를 줄 것으로 예상
판별형 모델은 1번 패러다임에 적합하며 생성형 모델은 2,3 패러다임을 추가로 지원
모르는 개념
•
사전 학습
◦
사전 학습 임베딩
▪
word2vec 등, 대규모 데이터로 학습된 단어 임베딩을 사용하는 것
▪
한 단어의 하나의 임베딩 → 동의어/다의어 구분 X
▪
사전 훈련 언어 모델로 극복
◦
사전 학습 언어 모델
▪
LSTM을 이용할 때, 그 다음 단어를 예측하도록 훈련
▪
레이블이 필요가 없다.
▪
이를 이용해서 문맥이 주어지면, 단어에 대한 임베딩을 준다.
•
전이 학습
◦
사전 학습된 거를 다른 모델의 파인 튜닝에 잘 넣어주는 것
◦
임베딩 값을 입력으로 받거나, 해당 가중치를 초기화값으로 사용하거나.
•
BERT
◦
사전 학습 + fine_tuning 훈련 과정
•
BERT는 discriminative LLM인가?
◦
그렇다고 한다. 왜인지는 살펴봐야할 지점
▪
양방향으로 문장을 학습하며, 빈 칸을 만들고 거기에 들어갈 말뭉치를 채우는 것
◦
GPT는 단방향
▪
그 다음 말뭉치를 예측하는 것
Discriminative LLM을 사용한 추천
Fine-tuning
•
사전 학습된 모델을 파인-튜닝 시켜서 다양한 NLP 태스크를 수행하는 것
•
풍부한 언어 표현력을 이미 배운 애들을 이용해서 특정한 태스크나 도메인에 적용하기
•
학습된 파라미터를 이용해서 초기화하고 추천 특화 데이터셋에 대해서 학습시키기
•
이 데이터셋은 주로 user-item 상호작용과 아이템, 유저 프로필과 다른 관련있는 정보들에 대한 표현들을 포함한다.
•
사례 연구
◦
Qiu et al.
▪
사용자의 표현을 학습하기 위해 컨텐츠가 풍부한 도메인을 활용하는 새로운 사전 훈련 및 파인 튜닝 기반 접근 방식 U-BERT를 제안
▪
사용자와 아이템 리뷰 사이의 의미 상호작용을 포착하기 위해 리뷰 공동 매칭 계층이 설계
◦
UserBERT
▪
두개의 self-supervision task가 라벨링되지 않은 행동 데이터에 대한 사용자 모델 사전 훈련을 위해 두 가지 self-supervision task가 포함됨. medium-hard 대조 학습, 마스크된 행동 예측과 행동 시퀀스 매칭으로 캡처된 본질적인 사용자 관심과 관련성을 통해 정확한 사용자 표현을 훈련
◦
BERT는 순위 매기기 작업도 잘함.
▪
BECR은 deep contextual token interaction과 전통적인 어휘 매칭 기능을 결합해서 순위 재지정 방식을 제안.
▪
BECR는 사전 계산 가능한 토큰 임베딩을 사용하여 쿼리 표현을 효과적으로 근사, 즉석 순위 매김 관련성과 효율성 사이에 합리적 절충을 허용
•
쿼리 표현을 근사?
•
ad-hoc relavance
•
uni-grams
•
skip-n-grams
◦
Wu et al (2022)
▪
쿼리와 제품 간의 어휘 불일치 이슈를 다루기 위해, 파인 튜닝된 도메인 특화 BERT를 사용한 제품 순위 메기기를 위한 엔드투엔드 다중 작업 학습 프레임워크를 제안
▪
풍부한 참여 데이터를 활용하기 위해, 작업 간 전송 확률과 mixture-of-experts layer를 사용함.
◦
그룹 추천, 검색/매칭, CTR 예측 등도 있다.
◦
특히 pre-train, fine-tuning 메커니즘은 연속적 또는 세션 기반 추천 시스템에서 중요한 역하을 함.
▪
BERT4REC, RESETBERT4REC
◦
훈련 전략의 이점을 활용했을 뿐, LLM을 추천 필드로 확장시킨 것은 아니었으므로 우리의 포커스가 아니다.
◦
시퀀스 표현 학습 모델인 UniSRec은 아이템의 설명 텍스트와 연결하여 다른 추천 시나리오에서 전이 가능한 표현을 학습하는 BER fine-tuning 프레임워크임.
◦
컨텐츠 기반 추천, 뉴스의 경우 NRMS, Tiny-NewREC,PREC은 LLM을 활용하여 뉴스 추천 강화
◦
Yuan et al은 대규모 실험을 통해 MoRec이 IDRec과 동등하거나 더 나은 성능을 발휘함을 발견
▪
non-cold-start 아이템 추천하는 상황임에도
▪
IDRec은 ID를 기반으로 한 추천 시스템
▪
MoRec은 아이템의 다양한 특성이나 성질을 나타냄
◦
BERT 파인 튜닝을 추천 시스템에 통합하는 것은 강력한 외부 지식과 개인화된 사용자 선호를 결합하여 추천 정확도를 높이고 동시에 제한된 historical data를 가진 새로운 아이템에 대해 cold-start를 다루는 능력을 획득하기 위함.
Prompt Tuning



특정 목표 함수를 디자인하는 대신, 프롬프트 튜닝은 사전 훈련된 손실과 하드.소프트 프롬프트와 label word verbalizer를 통해 추천 튜닝 목적을 align 시키려고 함.
•
사례 연구
◦
Penha and Hauff
▪
BERT의 마스크드 Language Modeling 헤드를 아이템 장르의 이해를 밝히는 데 사용함.
▪
Next Sentence Prediction 헤드와 Similarity of representation을 관련성, 관련성 없는 검색 비교하는데 쓰고, 추천 쿼리와 문서 인풋을 비교하는데도 썼다.
▪
이 실험은 BERT가 fine-tuning 없이 충분히 순위 메기기에서 관련 있는 아이템을 우선시 할 수 있음을 보여줌.
◦
Yang et al
▪
대화형 추천 시스템, BERT 기반 아이템 인코더는 각 아이템의 메타데이터를 임베딩으로 직접 매핑함
◦
Prompt4NR은 prompt learning paradigm을 뉴스 추천하는데 사용했다.
▪
이 프레임워크는 사용자 클릭 예측 목표를 cloze-style mask 예측 과제로 재정의함.
▪
다중 프롬프트 앙상블을 활용해서 추천 시스템 성능이 눈에 띄게 향상됨.
▪
프롬프트 앙상블의 효과성을 강조함.
Generative LLM for Recommendation
생성 모델이 좀 더 나은 자연어 생성 능력을 가짐.
판별형 모델 베이스 접근이 LLM에 의해 학습된 표현을 추천 도메인에 맞추는 것과 다르게, 생성형 모델 기반의 작업은 추천 태스크를 자연어 태스크로 해석하고 in-context learning, prompt-tuning과 instruction tuning같은 기법을 적용해서 LLM이 곧바로 추천 결과를 낼 수 있도록 함.
Non-tuning 패러다임
LLM은 보지 않은 태스크에 대해서 많은 강점을 보여옴. 추천 기능이 이미 있다고 보고, 이 능력을 특정한 프롬프트를 통해서 발현시킬 생각 중. 지시나 In-Context Learning을 적용해서 추천 태스크를 모델 파라미터 튜닝 없이 되도록 함.
Prompting


•
어떻게 하면 LLM이 추천 태스크를 좀 더 잘 이해할 지 고민함.
•
사례 연구
◦
Liu et al
▪
평점 예측, 순차적 추천, 직접적 추천, 설명 생성, 리뷰 요약 이 다섯 가지 일반적인 추천 작업에서 ChatGPT의 성능을 평가함
▪
일반적인 추천 프롬프트 구성 프레임워크 제안
•
작업 설명, 추천 작업을 자연어 처리 작업에 적합하게 만듬
•
행동 주입, user-item 상호작용을 LLMs이 사용자 선호와 필요를 잘 캡쳐할 수 있도록 함.
•
형식 지시로 출력 형식을 제한하고 추천 결과를 더 이해하기 쉽고 평가할 수 있게 함.


◦
Dai et al
▪
ChatGPT의 추천 능력을 세 가지 정보 검색 작업인 포인트별, 쌍별, 목록별 순서 매기기에 대해서 능력을 시험해봄
▪
태스크별로 다른 프롬프트를 제안하고 프롬프트의 처음 부분에 role을 명시해서 도메인 적응 능력을 향상 시킴
◦
Sanner et al
▪
아이템만 있는 경우, 사용자의 선호에 대한 설명만 있는 경우, 두 개가 결합된 경우 이렇게 세 가지 프롬프트 템플릿을 설계해서 다양한 프롬프트의 입력을 평가함.
▪
zero-shot, few-shot 전략이 오로지 언어 기반 선호도에 기반한 추천을 만드는데 매우 효과적임을 발견
▪
콜드 스타트 시나리오에서 아이템 기반 협업 필터링 방법이랑 비교해도 경쟁력이 있다.
◦
MINT
▪
사용자의 상호작용 데이터를 기반으로 한 프롬프트로 사용자의 의도를 요약하기 위해 InstructGPT를 사용해 합성 내러티브 쿼리를 생성
▪
…????
▪
KAR이 어떤 문제를 해결했다.
◦
Sileo et al은 영화 추천 프롬프트를 GPT-2의 사전 훈련 말뭉치에서 추출함.
◦
Hou et al은 순차적 추천 능력을 향상시키기 위한 두 가지 프롬프트 도입
▪
사용자 상호작용 이력에서 순차적 정보를 인지하게 함. 부트스트래핑은 후보 아이템을 여러 번 섞어 순위를 매기기 위한 평균 점수를 취함으로써 위치 편향 문제를 완화
◦
Sun et al은 슬라이딩 윈도우 프롬프트를 제안
▪
각 시간에 윈도우 내의 후보들만 순위를 매기고, 윈도우를 뒤에서 앞으로 슬라이딩 한 후 이 과정을 여러 번 반복하여 전체 순위 결과를 얻음
◦
GENRE
▪
뉴스 추천을 위한 세 가지 특징 강화 작업을 위해 세 가지 프롬프트를 만들었다.
▪
ChatGPT를 이용하여 뉴스 제목을 요약에 따라 정제, 사용자 독서 이력에서 프로필 키워드를 추출,
▪
historical interaction을 풍부하게 하는 합성 뉴스를 생성
◦
NIR
▪
사용자 신호 키워드를 생성, 사용자 상호작용 이력에서 대표 영화를 추출하기 위해 두 가지 프롬프트를 설계하여 영화 추천을 향상
◦
LLM을 전체 시스템의 컨트롤러로 활용하는 방향
▪
ChatREC은 ChatGPT를 중심으로 대화형 추천 프레임워크 설계, 다중 턴 대화를 통해 사용자 요구를 이해하고 기존 추천 시스템을 호출하여 결과 제공
•
ChatGPT는 데이터베이스를 관련있는 컨텐츠를 찾기 위해 프롬프트를 보완하고 콜드 스타트 아이템 문제를 해결함.
▪
GeneRec
•
생성 추천 프레임워크를 제안, LLM을 컨트롤하는데 사용한다.
•
기존 아이템을 추천할 시기를 제어하거나 AIGC 모델로 새로운 아이템을 생성
▪
RecAgent는 LLM을 지능형 시뮬레이터로 추가 활용하여 가상 추천 환경 개발.
•
사용자 모듈과 추천자 모듈로 구성됨. 사용자 모듈은 추천 사이트 탐색, 사용자와 상호작용 및 소셜 미디어에 게시할 수 있게 하고, 추천자 모듈은 맞춤형 검색 및 추천 목록을 제공하여 다양한 모델 설계 지원
▪
환경 내 사용자는 LLM에 기반한 행동을 취하며 실제 세계의 행동을 거울처럼 자연스럽게 발전할 수 있다. 이 프로젝트는 RL 기반 추천에 대한 피드백 및 시뮬레이션 및 소셜 미디어 상의 사용자 간 정보 전파 과정 추적과 같은 여러 응용 프로그램에서 잠재적 활용 가능성 보여줌.
In-context Learning
인풋 묘사와 라벨 쌍 몇 개 정도로 unseen input에 대해서 파라미터 업데이트 없이 예측하는 것.
•
사례 연구
◦
Sequential Recommendation
▪
Hou et al
•
입력 상호작용 시퀀스를 augment 했다.
•
입력 상호작용 시퀀스의 prefix와 이에 해당하는 successor를 예시로 쌍을 만들어 넣었다.
▪
Liu et al, Dai et al
•
In-context 학습 방법이 LLM의 추천 능력을 향상 시킬 것임을 보여줌.
•
적절한 데모는 LLM의 출력 형식과 내용을 제어하는 데 사용될 수 있으며, 이는 규칙적인 평가 지표를 향상시킬 수 있습니다.
•
이것은 안정적이고 강력한 추천 시스템을 개발하는 데 중요합니다.
◦
근데 프롬프팅과 비교해서, 몇 개 연구만 진행이 되었고, 여기에는 많은 의문점이 남아있다.
◦
데모 예시와 데모 예시의 숫자가 추천 기능에 영향을 끼칠 수 있는지 잘 모르겠다.
Tuning 패러다임
프롬프트 러닝이란?


•
Zero/Few shot 능력을 LLM이 가지고 있음
•
프롬프트 디자인을 통한 random guess 보다 더 한 추천 성능을 낼 수 있다.
◦
그치만 아직은 파인 튜닝된 추천 모델 성능을 초과하지 못한다.
◦
따라서 추가적인 파인 튜닝 또는 프롬프트 러닝으로 LLM의 추천 능력을 강화하고자 한다.
•
파인 튜닝, 프롬프트 튜닝, 지시 사항 튜닝
•
discriminative랑 generative 모델의 방법이 비슷함.
◦
LLM은 특성 추출 인코더로 보통 작용
◦
LLM의 파라미터는 downstream task의 loss function 이후 파인 튜닝됨.
•
프롬프트 튜닝
◦
언어 모델 Loss를 사용하여 훈련됨.
◦
특정 작업에 중점을 둔다.
•
지시사항 튜닝
◦
언어 모델 Loss 사용하여 훈련
◦
다양한 유형의 지시사항을 가진 여러 작업에 대해 훈련됨
•
더 나은 제로 샷을 학습할 수 있다.
Fine Tuning
•
Discriminative LLM이랑 근본적으로 비슷함
사례 연구
•
Petrov & MacDonald
◦
GPTRec: GPT-2 기반 sequential 추천 모델
◦
BERT4Rec과 달리 생성 모델을 기반
◦
메모리 효율성을 위해 SVD Tokenization을 사용하고 Next-K 생성 전략을 더 유연하게 사용함
•
Kang
◦
historical interaction을 프롬프트로 포매팅하고, 각 interaction은 아이템에 대한 정보로 표현됨
◦
평점 예측 작업을 각각 multi-class 분류와 회귀 두 가지 다른 작업으로 나눠서 구성
◦
250M ~ 540B까지 여러 크기의 LLM 조사 후, 제로 샷, 퓨 샷 등 파인 튜닝 시나리오에서 성능을 평가
•
Li
◦
강력한 LLM을 텍스트 인코더로 사용하면 추천 정확도가 향상될 수 있음을 밝힘
◦
엄청 큰 언어 모델이 사용자와 아이템의 보편적 표현을 제공하지는 않음
◦
간단한 ID 기반 협업 필터링은 warm 상황에서 여전히 좋은 방법임
Prompt Tuning
유저/아이템 정보를 입력으로 받아 사용자의 선호도를 출력 or 관심 아이템을 출력
•
사례
◦
Bao
▪
2단계를 거침
▪
Alpaca에 의해 제공된 self-instruct data로 한 번 fine-tuning
▪
historical sequence를 입력으로 Yes or No를 출력함
◦
Ji
▪
GenRec: 추천할 타겟 아이템을 직접 생성하는 LLM 기반 생성적 추천 방법
▪
아이템을 프롬프트로 변환하는 입력 생성 함수를 사용하고
▪
LLM을 사용해서 추천하는 아이템을 생성하도록 제안.
◦
Chen
▪
다단계 접근 방식 제안
▪
사용자 선호도 요약 생성을 위해 LLM을 활용함
•
음악, TV 시청 이력을 분석해서 “팝”, “판타지” 같은 요약을 생성
▪
더 작은 후보군을 얻기 위해 검색 모듈을 활용
▪
interaction 이력, 자연어 기반 사용자 프로필, 검색된 후보를 결합해서 LLM에 입력하는 자연어 프롬프트 구성
•
LLM의 장점은 특정 도메인에 파라미터를 효율적으로 맞출 수 있는 능력, 이게 탐색된 분야는 온라인 채용 시나리오임.
◦
GIRL
▪
JD를 생성하기 위해 LLM을 사용함
▪
추천에 있어서 explanation과 적절성을 향상 시킴
◦
GLRec
▪
LLM recommender를 사용하여 behavior graph를 해석하는 meta-path prompt 생성기
▪
prompt bias를 줄이기 위해 path augmentation 모듈을 통합함.
◦
Du
▪
GAN을 사용해서 저품질 이력서와 생성된 고품질 이력서를 짝짓는 LLM 기반 프레임워크 도입.
▪
이 과정으로 이력서 표현을 잘 고쳤고, 추천 결과를 개선함.
•
다른 여러 작업
◦
Jin
▪
관심을 가질 법한 제품의 제목을 LLM으로 생성
▪
mT5 모델을 fine-tuning
▪
데이터셋에 기반한 generative object를 사용해서 mT4 모델을 파인 튜닝함.
▪
근데, 마지막 제품 제목을 결과로 취하는 것이 파인 튜닝 언어 모델 성능을 능가함.
◦
Friedman (RecLLM)
▪
대화 관리 모듈
•
사용자와 대화
▪
랭커 모듈
•
사용자 선호도와 일치
▪
LLM 기반 사용자 시뮬레이터
•
합성 대화를 생성
◦
Li (PBNR)
▪
사용자 행동 및 뉴스를 텍스트로 기술
▪
개인화 프롬프트는 input-target 템플릿을 설계해서 생성
▪
프롬프트 필드는 raw data의 정보에서 대체됨.
▪
훈련 과정 전반에서 랭킹 손실과 언어 생성 손실을 합침.
◦
Li
▪
추천 작업을 쿼리 생성 + 검색 문제로 간주
▪
LLM을 사용하여 다양하고 해석 가능한 쿼리를 생성
•
더 나은 성능을 위해 프롬프트 학습을 활용하도록 제안
◦
UniCRS
▪
knowledge-enhanced prompt 학습에 기반한 통합 대화형 추천 시스템
▪
LLM의 파라미터를 고정, 프롬프트 학습 통해서 응답 생성/아이템 추천하는 소프트 프롬프트
◦
LLM 생성 능력 기반, 설명 제공
▪
Discrete, Continuous 모두 시도
▪
두 가지 전략을 제시; regularization으로써 sequential tuning과 추천, 두 가지 전략을 제안
Instruction Tuning




다양한 유형의 태스크에 대해 지시사항으로 find-tuning 됨.
LLM은 인간의 의도에 맞는 답변을 제시 + 더 나은 zero-shot 능력 달성
사례
•
Geng
◦
다섯 가지 다른 유형의 instruction에 대해 T5 모델을 파인 튜닝
◦
sequential rec, 평점 예측, 설명 생성, 리뷰 요약, direct rec 작업
◦
instruction tuning 후, unseen personalized prompt에 대해서 zero-shot generalization 능력을 학습
•
Cui
◦
점수 매기기, 생성, 검색; 세 가지 유형에 대해 M6 모델을 파인 튜닝
•
Zhang
◦
선호도, 의도, 작업 형태 라는 관점으로 instruction format을 설계
◦
39개 instructino 템플릿을 설계
◦
3B FLAN-T5-XL 모델에 대한 instruction tuning을 위한 개인화된 지시사항 데이터를 자동으로 생성함.
◦
GPT-3.5를 비롯한 여러 경쟁 기준선을 능가할 수 있음
Findings
5.1 모델 편향
Position Bias
•
사용자 행동 시퀀스와 추천 후보 등이 텍스트에 순차적 형태로 입력된다.
•
이건 언어 모델에서 위치 편향으로 이어질 수 있음
◦
candidate의 순서가 추천 모델의 순위 결과에 영향을 미칠 수 있음
•
시퀀스의 행동 순서를 잘 포착하지 못함.
•
Hou는 position bias를 완화하기 위해, 랜던 샘플링 기반 bootstraping을 사용; 최근에 상호작용한 항목을 강조하여 행동 순서를 강화
◦
적용적이지 않았다.
Popularity Bias
•
훈련 corpus 에서 자주 언급된 인기 항목이 더 높은 추천 순위를 차지하는 경향
•
pre-train corpus를 어떻게 구성하냐와 관련이 있어서, 어려운 문제이다.
Fairness Bias
•
pre-trained LM은 공정성 문제를 나타냄.
•
특정 작업에 관련된 개인의 인구 통계학적 특성에 영향을 받음.
•
사용자를 특정 그룹에 속한다고 가정하는 추천을 생성, 배포시 논란의 여지가 있음
◦
성별이나 인종에 의한 추천 결과 편향
◦
공평하고 편견 없는 추천을 보장하기 위해 중요함.
5.2 추천 프롬프트 디자인
사용자/아이템 표현
•
추천 시스템에서는 사용자/아이템 표현을 위해 Discrete, Continuous feature를 활용함
•
대부분의 기존 LLM 기반 작업은 아이템을 나타내기 위해 이름만 사용; 사용자를 나타내기 위해 아이템 이름 목록만 사용; 이는 모델링하기에 불충분함.
•
약간은 다른 사용자의 행동 시퀀스를 모두 자연어로 바꿔야함.
◦
클릭, 장바구니 추가, 구매 등등
◦
ID 같은 특성은 전통적인 추천 모델에서 효과적임이 입증되었으나, 프롬프트에 통합하여 개인화된 추천 성능을 향상 시키는 것은 어려움.
제한된 컨텍스트 길이
•
행동 시퀀스 길이와 후보 아이템 수를 제한함
◦
최적이 아닌 성능을 낼 수 있음
•
행동 시퀀스에서 대표 아이템을 고르는 것
•
후보 목록을 위한 sliding window 전략 등
5.3 Promising Ability
Zero/Few shot 추천 능력
•
LLM은 여러 추천 작업에서 인상적인 Zero/Few shot 능력을 가지고 있음
◦
LLM의 매개변수를 변경하지 않는다는 점이 주목할 가치가 있다.
◦
제한된 데이터로 콜드 스타트 문제를 완화할 수 있는 잠재력을 가지고 있음
◦
이를 위한 효과적인 예시를 선택하는데 있어 명확한 Instruction이 필요
◦
Zero/Few 샷의 추천 능력에 있어서 결론을 내리기에는 더 많은 도메인에서 실험 결과가 필요하다.
•
설명 가능한 추천을 위해 LLM을 쓰는건 괜찮다.
◦
파인 튜닝 없이도 In-Context learning에서 ChatGPT가 일부 전통적인 지도 학습 방법보다 더 나은 성능을 보임.
◦
ChatGPT의 설명은 실제보다 더 명확하고 합리적으로 느껴진다.
◦
설명 가능한 추천에서 Fine-tuning된 LLM의 성능은 유망할 것.
5.4 평가 문제
Generation Controlling
•
세심하게 설계된 instruction을 제공해서 추천 시스템으로 활용함; 출력은 instruction 형식에 엄격하게 준수
◦
실제에서는 원하는 형식에 벗어날 수 있음
◦
잘못된 형식의 응답을 생성, 답변 제공을 거부할 수 있음
•
훈련 데이터와 auto-regressive 훈련 방식으로 인해, 여러 아이템으로 순위 문제를 처리하는데 능숙하지 못하기에 리스트 형식의 추천 작업에서 잘 동작하지 않음.
◦
여러 항목의 순위를 정하는 실제 기준이 없어서 fine tuning으로 해결할 수 없다.
◦
sequence 기반의 auto-regression 훈련을 하기 힘들다.
•
PRP(Pairwise Ranking Prompting)은 LLM을 사용해서 리스트 방식 작업에 대해 pairwise-ranking을 제안; 모든 쌍을 열거하고 각 항목 점수를 생성한다.
◦
시간이 많이 소요된다.
◦
따라서 LLM의 출력을 더 잘 제어하는 것이 더 시급한 문제임
Evaluation Criteria
•
평점 예측 / 항목 순위 같은 표준 추천 작업인 경우 NDCG, MSE 같은 기존 지표를 사용 가능
•
LLM은 생성 능력도 있으므로, Generative Recommendation Task에 적합하다.
•
Generative Recommendation 패러다임을 따르면, Historical data에 나타나지 않은 항목을 생성하고 추천할 수도 있다.
◦
이 점에서 LLM의 생성적 추천 능력을 평가하는 것은 여전히 의문임.
Dataset
•
MovieLens, Amazon Books 등과 같은 벤치마크를 사용해서 추천 능력 & Zero-Few 샷 능력 테스트
•
두 가지 문제를 야기할 수 있음
◦
실제 산업 데이터셋에 비해 규목 작아서 LLM의 추천 능력을 완전히 반영하지 못할 수 있다.
◦
데이터셋은 사전 훈련 데이터에 나타난 관련 정보를 가질 수 있음. LLM의 Zero shot 학습 능력을 평가하는데 bias가 낄 수 있다.
▪
즉 적합한 데이터셋이 부족하다.
•
LLM의 능력과 관련된 일부 제한 사항도 있음
◦
특정 도메인 지식을 학습하는데 있어서 forgetting 현상이 발생할 수 있음.
◦
언어 모델 매개변수의 크기가 다양함에 따라 성능이 달라지고, 큰 모델을 사용하는 것은 계산 비용이 많이 나올 수 있음.
결론
•
추천 시스템을 위한 LLM 연구 영역을 검토
•
Discriminative / Generative 모델로 분류 → 도메인 적용 방식으로 살펴봄
•
fine-tuning, prompting, prompt tuning, instruction tuning 방식을 LLM based recommendation에서 봄.