
Abstract
•
recommendation은 task-specific architecture여서 1) transfer learning 어려움 2) generalization restriction이 있음 → 다른 도메인 적용이 어려움
•
이를 해결하기 위해서 P5를 제안
◦
이건 Text-to-Text 패러다임임
◦
언어로는 대부분의 task를 설명할 수 있다는 사실에 기반
◦
user-item interaction, user descriptions, item metadata, user review들이 전부 common format으로 바뀜 - 자연어 시퀀스
•
personalization과 recommendation을 더 잘하게 해줌
◦
deeper semantic을 capture
•
P5는 same language modeling objective로 pretraining 때 학습이 됨. 따라서 이건 다양한 downstream task에 foundation model이 됨.
◦
다른 modality와의 통합이 가능, instruction-based recommendation이 가능
•
zero-shot, few-shot 능력을 사용해서 extensive fine-tuning을 줄여줄 것임
◦
different user에 대해서 personalized prompt를 작성함으로써 달성 가능
Keywords
Recommender Systems; Natural Language Processing; Multitask Learning; Personalized Prompt;
Language Modeling; Unified Model
Introduction
역사를 요약하자면
•
feature engineering & learning
◦
logistic regression / collaborative filtering
▪
user-item interaction record를 가지고 사용자 행동 패턴을 모델링함
◦
Transferable representation
▪
One4all User Representation for Recommender Systems in E-commerce
•
여러 서비스에 대해서 공통된 user representation을 만들고자 함.
•
ShopperBERT라는걸 만들고, 이를 활용한 transfer learning을 시도. 이를 task 별로 from scratch한 모델과 비교
•
다양한 downstream에서 적용가능한 user feature를 뽑을 수 있었음
◦
특히 이건 cold-start problem을 해결하기 위해 다양한 auxiliary dataset을 배운 모델들보다 훨씬 뛰어남.
▪
Scaling Law for Recommendation Models


◦
Multitask prompt-based training
P5는 다수의 추천 태스크를 한 번에 수행할 수 있음. prompt 기반의 자연어 task를 이용한 unified sequence to sequence framework를 통해서. user-item 정보와 해당하는 정보는 personalized prompt template에 integrate 된다.
advantage
1.
NLP 태스크로 전부 바뀐다.
a.
Language 기반은 다양한 feature를 텍스트 템플릿으로 담기에 좋기 때문에, feature-specific encoder를 디자인할 필요가 없다.
b.
다양한 semantic과 지식을 training corpora에 담을 수 있게 됨.
2.
task-specific architecture / objective function을 사용한 것이 아니라 language modeling loss를 쓰고 text-to-text encoder-decoder architecture를 사용함.
a.
모든 personalized task를 conditional text generation problem으로 다룬다.
3.
instruction-based prompt를 통해 P5는 충분한 zero-shot 능력을 가지게 된다.
a.
새로운 personalized prompt와 unseen item에 대해
5가지 태스크 그룹에 대해서 테스트를 진행함. → 이를 통해 zero-shot generalization ability를 시험
Contribution
•
다양한 추천 태스크를 하나의 conditional language generation framework로 통합한 첫 예시
•
5가지의 추천 태스크에 대해서 personalized prompt collection을 완성
•
P5는 좋은 성능을 보여줌
•
P5는 sufficient zero-shot generalization 능력을 새로운 프롬프트나 새로운 아이템에 대해서도 보여줌
Related Work
Unified Framework
T5: text-to-text encoder-decoder framework
GPT-3: autoregressive language modeling
다양한 태스크를 통합된 모델로 해결하고자 함.
이를 통해 large-scale language task 또는 cross-modality application를 시도하고자 함. 모든 문제를 자연어 형식으로 처리하고자 했음. 하지만 personalized 하게끔 하지는 못했다!
universal한 representation을 만들고자 하였으나 - easily transferrable하게끔 - additional finetuning이 필요하다는 것임.
반면에 P5는 personalization을 encoder-decoder Transformer model에 더했고, 다양한 추천 시나리오에 적용가능하게끔 일반화가 가능했음.
Prompt Learning
pretrain, prompt, predict 패러다임을 따름.
한 가지 방법이 proper discrete prompt를 만드는 것.
다른 방법이 continuous vector embedding을 프롬프트로 사용하는 것
instruction-based 프롬프트는 상세한 task description을 포함하고, 좀 더 자연어에 가깝다.
large-scale NLP dataset을 기반으로 한 pretrained model을 human-readable prompt로 fine-tuning 했더니 더 좋은 zero-shot 능력을 얻게 되더라. 이에 기반해서 personalized prompt 컬렉션을 만들었고 sequence to sequence model을 여러 다양한 related task에 대해 훈련 시킴
NLP For Recommendation
NLP와 추천은 함께 성장함
1) explainable recommendation; text explanation generating이 가능하기 때문
2) sequential recommendation; user interaction history를 word token sequence로 인지
3) text feature extraction; informative text encoding을 뽑아내는 것
4) conversational recommendation; 사용자의 의도를 유추하고 interactive dialog format으로 주는 것
sequential recommendation, explanation generation를 커버하고, 추가적으로 다른 추천 문제인 rating prediction, top-k recommendation, review summarization에 대해서 진행해보고자 함.
Zero-shot and Cold Start Recommendation
Recommender System의 성능은 training data에 좡된다. 근데 history record가 제한된 상황에서도 항상 zero-shot 케이스가 나타남. 좋은 일반화 능력이라고 보여진다.
사용자와 아이템이 새로운 system에 들어왔을 때 해결 방법
1.
content feature를 학습하는 것
a.
interaction record가 없어도 추론이 가능하게끔
b.
다른 auxiliary domain으로부터 표현을 transfer하는 것
2.
zero-shot or few-shot 추천
a.
단순히 cold-start 케이스 뿐만이 아니라, 새로운 도메인에 대한 adaption도 포함함.
b.
domain adaptation의 경우, meta learning, causal learning framework를 통해 달성 가능함.
c.
P5가 auxiliary domain에 대해 pretrained 하고, target domain의 문제를 풀게끔 했음.
i.
user는 P5가 이미 알고 있는데, item의 경우에는 이전에 본적 없는 경우
Personalized Prompt Collection
rating prediction task family
1.
user,item 정보를 주고 1부터 5까지 바로 예측하도록
2.
사용자가 해당 항목에 점수를 줄지
3.
해당 아이템을 좋아할지, 안 좋아할지
Sequential recommendation task family
1.
user interaction history를 통해 바로 다음에 올 item을 맞추는 것
2.
user interaction history가 주어졌을 때, 가능한 next item을 후보 리스트에서 골라오는 것. 하나만 골라온다.
3.
주어진 아이템이 interacted 될지 안 될지
explanation task
1.
user/item information에 대해서 직접 설명
2.
feature word를 힌트로 설명을 생성
Review 관련 태스크
1.
review comment 요약
2.
review comment로 부터 rating 예측
Direct recommendation
1.
아이템을 유저에게 추천해줄지 말지 - Yes or No
2.
candidate list에서 유저에게 가장 어울릴 법한 item을 추천해주는 것
프롬프트를 이용해서, 우리는 raw data에서 input target pair를 구성할 수 있음.
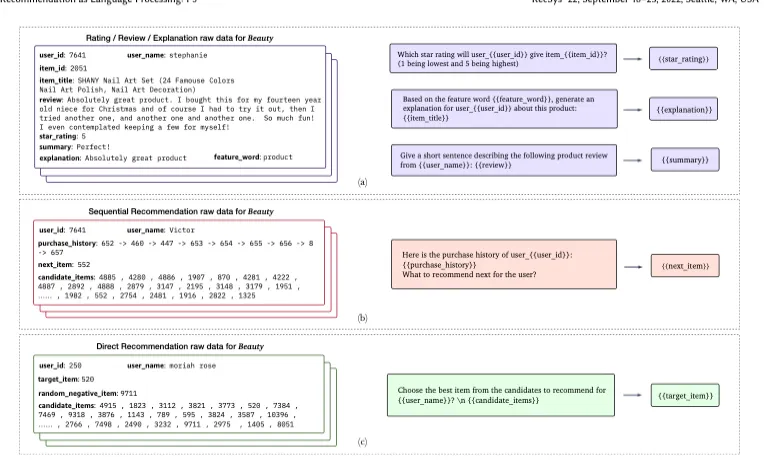
이런 식으로 prompt를 만들어낼 수 있음
전체 데이터는 rating, review, explanation 으로 구성되며, sequential과 direct의 경우에는 history 데이터를 사용한다는 점에서 조금 다르다.
pretraining에서는 다른 태스크 family의 input-target pairs를 전부 다 학습시킴
전부다 하는 거는 아니고, 일정 portion만 학습시킴
prompt에 대해서 negative item도 select 해놓음. prompt가 만약에 candidate list를 필요로 하는 경우
The P5 Paradigm And Model
P5 Architecture
앞에서 소개한 방식으로 personalized prompt를 뽑아놓으면, large amount of available pretraining dat가 만들어짐.
모든 pretraining data는 통일된 format의 input-target token sequence를 공유함. 이는 task 간 경계를 허무는데 중요하다.
P5는 기본적인 encoder-decoder framework를 기반으로 구축됨.
transformer 블럭을 encoder와 decoder를 구성하는데 사용함.
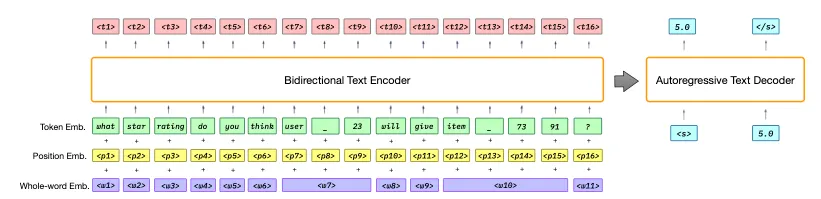
•
embedding + position + whole-world embedding
•
decoder attends to both the previously generated token y<j and the encoder output t and predicts the probability distribution of future tokens
◦
이전에 만들어진 아웃풋과 encoder output t에 대해서 주의를 기울이면서 미래 토큰의 확률 분포를 예측함.
•
nll loss를 학습함.
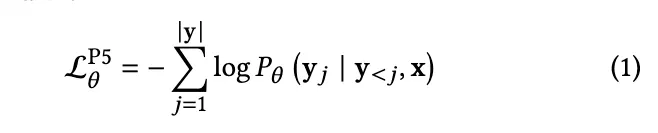
Recommendation with Pretrained P5
rating, explanation, review task는 greedy decoding을 답변을 생성하는데 사용
sequential과 direct recommendation은 target output으로서 item list를 요구함.
sequential의 경우, beam search 를 이용해서 potential next item의 리스트를 만들어내고, all-item setting 하에서 평가함.
direct recommendation의 경우, candidate set에서 추천 아이템을 예측하는데, m 중 하나만 positive sample임. beam search를 사용해서 potential target item의 리스트를 decode함.


Experiments
•
RQ1: task-specific method에 대비해서 performance
•
RQ2: enough zero-shot generalization ability를 가지느냐(unseen personalized prompted / existing or new items)
•
RQ3: scaling law for P5: model size, task family의 수, number of prompt
•
RQ4: 구현 시 더 좋은 방법 : user/item에 대해서 extra token 붙이기 <user_23> vs 여러 sub-word unit으로 쪼개기 (기존 방법)
•
P5 pretraining 하는데 얼마나 걸리는지
Experimental Setup
1.
Dataset - 4가지 real world 데이터셋 사용
a.
Amazon: 29가지 카테고리의 products
i.
Sports & Outdoors, Beauty, Toys & Games
b.
Yelp: business recommendation을 위한 user rating과 review
i.
공간 부족으로 인해서 Appendix에 넣음.
ii.
다른 데이터셋과 비슷한 트렌드를 보여줌
2.
Task splits
a.
training: validation: testing = 8:1:1
b.
각 item과 user가 training set에 최소한 하나는 들어가게 함.
i.
training에 없는데, testing에는 있게끔 안 했다는 뜻
c.
리뷰를 사용해서 item feature를 구성하고, 리뷰에서 item feature word를 언급한 문장을 리뷰에서 뽑아서 user의 기호에 대한 설명으로 집어 넣음
d.
sequential recommendation에 대해서, 마지막 아이템이 테스트로 사용됨.
i.
마지막꺼 바로 전이 validation data로 사용됨.
ii.
나머지가 training
iii.
이 작업에 맞춰서 direct recommendation도 진행함
3.
Implementation Details
a.
pretrained T5 checkpoint를 백본으로 사용함.
i.
P5-S, P5-B
ii.
P5-S는 6 layer가 encoder, decoder에 대해서 존재. 512차원에 8 head attention이고, 파라미터는 60.75 백만개
iii.
P5-B
1.
12개 블록. 768 dimensionality이고, 12-head attention 존재. 파라미터는 223.28백만개.
b.
Tokenizer로 SentencePiece 사용
c.
~~~ 생략
4.
Metrics
a.
rating: RMSE, MAE를 사용
b.
sequential: top-K Hit Ratio, NDCG를 사용
c.
explanation generation/ review summary: BLEU-4를 사용
5.
Baseline of Multiple Tasks
a.
Rating
i.
해당 태스크는 user-item rating/interaction 데이터만 가지고, content나 side information이 제공되지 않음.
ii.
MF, MLP를 베이스 라인으로
b.
Direct Recommendation
i.
BPR-MF
ii.
BPR-MLP
iii.
SOTA contrastive learning based collaborative filtering 모델인 SimpleX가 사용
c.
Sequential Recommendation
i.
S-Rec을 베이스로 사용
1.
Caser : sequential을 Markov Chain로 취급, convolutional neural network를 사용해서 user interests를 모델링함.
2.
HGN: hierarchical gating network를 적용해서 user behavior를 long, short term으로 학습
3.
GRU4Rec는 session based 추천
4.
BERT4Rec: BERT-style의 마스크 language modeling을 따라해서, bidirectional representation for sequential recommendation 함.
5.
FDSA: feature transition pattern에 집중하고, feature sequence를 self-attention 모듈을 통해 달성
6.
SASRec: self-attention mechanism을 적용, RNN기반과 markov 기반을 조화롭게 함
7.
S-Rec: self-supervised objective를 사용해서 sequential recommendation model이 더 item과 그들의 특성과의 관계를 발견하도록 함. S-Rec을 베이스로 사용
d.
Explanation Generation
i.
Attn2Seq: encode attributes를 벡터로 학습하고, attention mechanism을 사용해서 attribute vector를 전제로 한 review를 생성함
ii.
NRT는 GRU를 사용해서 user와 item id를 기반으로 설명 생성
iii.
PETER는 간단하고 효과적인 프레임워크로 user와 아이템 id를 사용해서 설명을 생성함
1.
modified attention mask of the transformer architecture임
2.
PETER+가 있음, explanation generation을 보조하기 위해 hint feature를 취함
e.
Review Related
i.
T0 사용
1.
T0, GPT-2를 베이스라인으로 사용; GPT-2는 이 작업 수행 못함
RQ1: task-specific method에 대비해서 performance
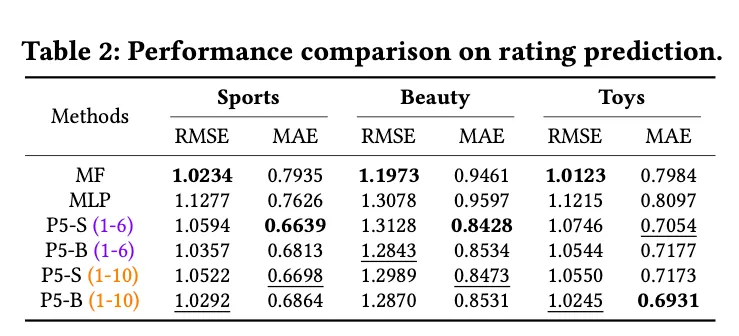
seen
•
P5-B가 MF에 비해서 더 나은 것을 확인할 수 있음
unseen
•
P5-B가 seen 데이터랑 비슷하다.
•
P5-S가 MAE에 대해서는 좋지만 RMSE는 조금 더 높다.
◦
overfitting 된 것이라 예상. 다른 태스크보다 rating prediction이 쉬우니까
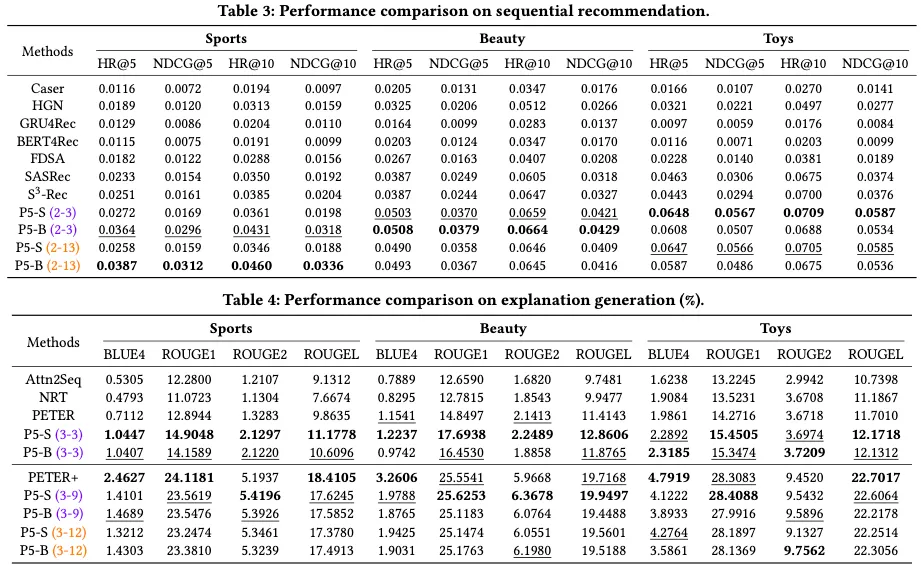
•
Sequential
◦
P5-B가 baseline을 훨씬 다 뛰어넘음
◦
Toys에 대해서는 P5-S가 P5-B를 뛰어넘기도 함
◦
P5가 user interaction history를 모델링하기에 좋음
•
Explanation Generation
◦
P5가 3-3 프롬프트랑 제공됬을 때, 모든 것에서 best performance임.
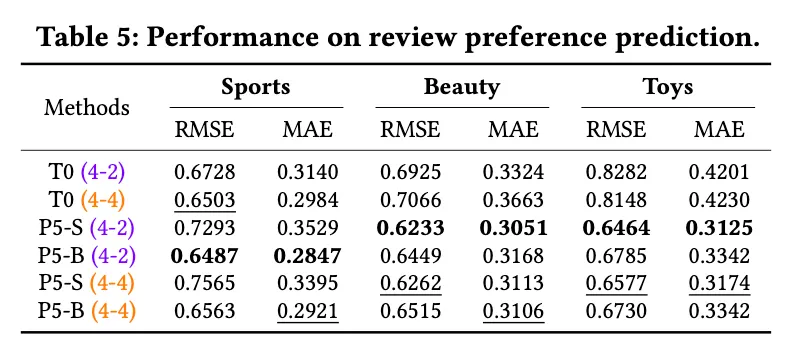
•
P5-S와 P5-B가 모두 좋은 성능을 보여줌
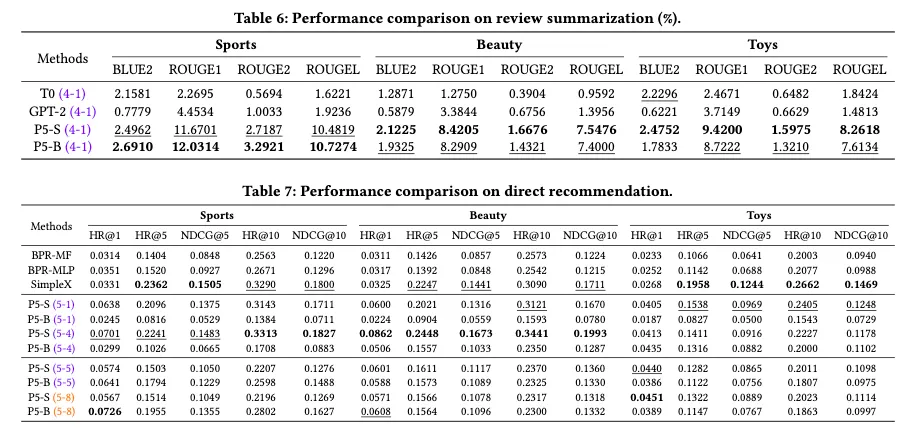
•
Review summarization
◦
P5-B랑 P5-S가 항상 좋았음
•
Direct Recommendation
◦
대부분 비슷하거나 좋았고 SimpleX에 비해서는 top-1 item ranking 맞추기에서 좋았다.
RQ2: enough zero-shot generalization ability를 가지느냐
Unseen Personalized Prompt
•
unseen prompt에 대해서 잘 함.
•
seen prompt를 뛰어넘는 경우도 있음
New Domain
•
rating prediction, like/dislike prediction이랑 explanation generation은 잘 하더라
•
direct explanation generation은 잘 못하더라.
결과
RQ3: Scaling Law
•
high quality personalized prompt가 많으면 zero-shot task를 좀 더 잘한다.
RQ4: Implementation
•
default setting이 더 낫다.
•
다른 것들은 비슷한 수준인데, sequential에서 훨씬 더 떨어짐