
Abstract
DNN은 추천 시스템에 많은 발전을 가지고 왔지만, 여전히 한계가 있다.
여기서 한계란
1.
사용자의 관심을 이해
2.
textual side information을 캡처링
3.
seen/unseen 추천 시나리오에 대한 일반화가 안 되는 것
4.
예측에 대한 설명력
LLM이 등장하면서, LLM이 가지고 있는 언어에 대한 기본적인 이해와 생성 능력들, 특히 일반화와 설명 능력을 보고, LLM의 능력을 추천 시스템에 적용시켜보고자 함. LLM 기반의 추천 시스템 연구를 체계적으로 다룰 필요가 있어서 이 논문을 시작함.
Pre-training, Fine-tuning, Prompting을 포함하는 다양한 관점에서 LLM 기반 추천 시스템을 보려고 함.
1.
users, items에 대한 representation를 학습하는데 LLM을 이용하는 방식에 대해 소개
2.
추천 시스템을 발전시키기 위한 LLM의 기술들을 리뷰
a.
pre-training
b.
fine-tuning
c.
prompting
3.
LLM이 줄 종합적인 토론을 해보자
Introduction

추천 시스템은 다양한 산업 분야에 적용되어왔다.
1.
엔터테인먼트
2.
이커머스
3.
job matching
4.
영화 추천
a.
영화는 영화 컨텐츠, 과거 사용자 히스토리를 기반으로 추천
b.
새로운 영화를 탐색하도록 도와줌
추천 시스템의 기본적인 아이디어는 interaction을 사용하는 것이고, 연관된 side information, 특히 textual information(아이템 제목과 설명, 사용자 프로필과 아이템에 대한 사용자 리뷰)를 이용해서 사용자와 아이템 간의 score를 예측하는 것이다.
구체적으로 1) 사용자와 아이템 간의 collaborative behavior 2) textual side information이 사용됨
DNN은 user-item 상호작용을 표현하는데 독보적인 능력을 가진다.
Ex) Sequential data를 위해서는 RNN이 user interaction sequence 간의 의존도를 파악하는데에 쓰임.
Ex) User의 온라인 행동을 고려할 때는 GNN이 가장 좋은 representation learning 기술이다.
DNN은 다른 여러 정보를 인코딩하는 것에도 이점을 가짐. 예를 들어 BERT-based method는 textual review에서 정보를 뽑아내고 활용하는 것에 쓰임
이럼에도 본질적인 한계를 가짐
1.
model scale과 데이터 사이즈의 한계 때문에, 이전 DNN 모델과 pre-trained LM은 textual knowledge를 잘 캡처하지 못함.
a.
이전의 것들은 user와 item의 textual knowledge를 이해하지 못함.
b.
낮은 자연어 이해 능력을 보여줬고, 추천 시나리오에서 최적이 아닌 예측 성적을 보여줌
2.
대부분의 추천 시스템은 주로 own task를 위해 특별히 디자인되었고, unseen recommendation 태스크에 대해서는 일반화 능력이 떨어짐
a.
user-item rating matrix에 대해 잘 훈련된 알고리즘이 있고, 이것이 영화 점수를 매기는 것이라면, 이걸로 top-k 영화 추천을 설명과 함께 하는 것은 힘들 수 있다.
b.
이건 이 추천 구조가 task-specific data과 추천 시나리오 specific한 도메인 지식에 의존적이기 때문이다
i.
추천 시나리오: top-k 추천, rating prediction, explainable recommendation
3.
존재하는 DNN 베이스의 추천 방식은 간단한 결정에 있어서는 좋은 성적을 내지만, 복잡하고 여러 스탭 결정에 있어서는 어렵다.
a.
multi-step reasoning은 여행 계획 추천에 중요한데, 왜냐하면 RecSys가 1차적으로 유명한 여행 명소를 골라야하고, 관광명소에 적합한 여행 일정표도 짜야하고 사용자 기호에 맞는 여러 dugod dlfwjddmf cncjsgodigkrl Eoans
LLM이 인상적인 일반화와 설명력을 갖추고 있어서, LLM으로 아직 보지 않은 task와 domain에 대해 좀 더 나은 일반화 능력을 가질 수 있을 것이라고 기대함. 구체적으로 특정 태스크에서 extensive fine-tuning이 필요한 대신, LLM은 학습한 지식과 추론 능력으로 새로운 task에 쉽게 fit이 가능할 수 있다. 이 때 적절한 instruction과 몇 가지 태스크 demo를 준다면.
In-Context learning과 같은 기술들은 LLM의 일반화 성능에 대해서 downstream task에 맞춘 fine-tuning이 필요없게 할 수도 있음. prompting strategy ( chain-of-thought) 같은 걸 쓰면 step-by-step 추론이 필요한 복잡한 의사 결정 프로세스도 할 수 있을 것이다.
그래서 LLM으로 하는 걸 기대함
최근에 LLM을 추천에 사용한 사례가 몇 가지 나왔다.
1.
Chat-Rec
a.
대화로 유저와 interact 하기 위해 ChatGPT를 이용해서 추천 정확도와 설명력을 향상 시킴.
b.
그리고 전통적인 RecSys로 만들어진 candidate set을 refine 했다.
2.
Zhang
a.
T5를 LLM 기반의 추천 시스템으로 적용해서, RecSys 인풋으로써 자연어를 입력 받게끔 해서, 유저가 explicit 선호를 잘 전달할 수 있도록 함.
b.
더 나은 추천 performance를 user-item interaction 기반보다 잘 나오게 했음
Pre-training, fine-tuning, prompting 이 세 가지 패러다임으로 살펴볼 거임.
Section2
•
RecSys와 LLM에서 관련 연구를 리뷰하고, 그들의 combination을 살펴볼거임
Section3
•
LLM 기반 RecSys의 두 가지 타입에 대해서 볼 것임
•
ID-based RecSys와 textual side information-enhanced RecSys
•
user와 아이템에 대한 표현을 배우는데 LLM의 이점
Section4,5
•
LLM을 RecSys에 적용하는 기술을 요약
◦
Pre-training, fine-tuning, prompting paradigm에 맞추어서
Section6
•
챌린지와 잠재적인 방향들에 대해서 토론
2. Related Work
2.1 RecSys
두 개로 나뉜다. 1) Collaborative Filtering 2) Content-based Recommendation
CF
CF는 historical data를 바탕으로 해서 나와 가장 비슷한 행동 패턴을 가진 사용자를 찾고 미래 상호작용을 예측하는 것; 가장 유명한 방법으로는 MF (pure user-item itneraction을 이용해서 사용자와 아이템에 대한 representation을 뽑아냄)
다른 방법으로는 유저와 아이템에 대한 unique identitiy를 인코딩해서 embedding vector를 만들고 matching score가 조금 더 쉽게 계산될 수 있도록 하는 것.
Content-based
user, item에 대한 부가적인 정보로 유저나 아이템의 표현력을 증가시킨다.
textual information에 집중할 것
representation learning 능력 때문에 딥러닝 기술이 recommender system에 효과적으로 적용됨.
Exmaple
•
NeuMF는 user-item간 비선형 상호작용을 일반적인 내적이 아니라 DNN으로 대체함으로써 표현함.
•
RecSys에 쓰이는 데이터가 그래프이기 때문에 GNN 테크닉도 노드의 표현력을 향상시키는 방법으로써 사용되고 message propagation 전략이 쓰인다.
•
textual knowledge를 결합하기 위해서, DeepCoNN이 CNN을 특정 아이템에 대한 사용자 리뷰를 인코드하는데 사용했고, 추천 시스템에서 rating prediction을 하는데 기여함.
•
neural attention framework인 NARRE는 아이템에 대한 rating을 예측하는 동시에 해당 예측에 대해 리뷰 레벨의 설명을 제공함.
LM이 자연어를 이해하는 능력이 좋기 때문에 많이 쓰이는 추세이다.
이 모델은 인간 자연어를 이해하는데 고안되어서, RecSys에게 더 많은 개인화된 추천을 해줄 수 있게 되었다.
•
뉴스 추천
•
약 추천
구체적으로 BERT4Rec이라는 순차적 추천 방법은 BERT를 유저 행동의 순차성을 모델링하는데 사용함
트랜스포머의 언어 생성에 초점을 맞추어서 아이템 추천을 함과 동시에 이에 대한 설명도 만들어줄 수 있다.
2.2 LLMs
모델 종류
pre-trained 모델 중에 BERT, GPT, T5 같은 모델들이 사용가능하다.
이런 모델은 세 가지 분류로 나뉜다. 1) 인코더만 사용 2) 디코더만 사용 3) 둘 다 사용
BERT, GPT, T5는 트랜스포머 구조에서 나온 것들임
BERT는 encoder-only 모델, 양방향 attention을 토큰 시퀀스에 사용해서 토큰의 왼쪽 오른쪽 컨텍스트를 모두 고려함; masked language modeling과 다음 문장 예측과 같은 태스크를 위해서 만든 것이라서, 컨텍스트 의미와 언어 뉘앙스를 잘 캡처한다.
이 과정은 Text를 벡터 공간으로 바꿔서 뉘앙스와 context-aware 분석이 가능하게 함
GPT는 트랜스포머 decore 구조를 기반으로 해서 단방향 단어 시퀀스 프로세싱을 위해 self-attention 메커니즘을 사용함. GPT는 언어 생성 태스크에 주로 적합하고, 임베딩 벡터를 다시 매핑시키고 가장 적합한 응답을 찾는다.
T5는 인코더-디코더 모델로서, text-to-text task를 다 다룰 수 있다. 모든 자연어 처리 문제를 text generation 문제로 바꿀 수 있다. 예를 들어서, 감정 분석 태스크를 text sequence로 변환할 수 있음.
sentiment: I love this movie 이런 식으로 인풋을 넣고 정답을 psotivie로 받는다. 이런 식으로 T5는 같은 모델, 목적,훈련 방식을 가지고 모든 태스크에 사용가능하게 하고, 다양한 NLP 태스크에 다재다능한 툴이 되었음
ICL
ICL 능력도 입증되었음. ICL은 pre-training을 통해 얻은 지식 말고, input context로 들어온 것들에 기반해서 답변을 하는 능력을 얘기함.
다양한 태스크에서 ICL을 활용하는 방법이 있다. (SG-ICL, EPR)
이런 작업은 ICL이 LLM으로 하여금 일반적인 답변이 아니라 인풋 컨텍스트로 하여금 대답을 만들도록 함.
CoT
LLM 추론 능력을 향상 시킬 수 있는 방법
프롬프트에 여러 단계의 추론을 데모와 함께 입력함으로써, 모델의 추론 과정을 가이드하는 것
CoT의 확장은 self-consistency 이다. 이건 대답에 대한 다수결 투표 메커니즘으로 구현됨.
STaR THOR, Tab-CoT와 같은 LLM의 CoT 적용 연구도 있음
모델이 생각 프로세스를 지도하는 프롬프트 셋을 제공함으로써 CoT는 모델이 효과적으로 생각하고 정확한 답변을 할 수 있게 함
LLM in RecSys
중요한 사례가 바로 아이템에 대한 사용자 평점 예측이다.
이건 historical user interaction과 기호를 분석해서 이뤄졌고, 추천 정확도를 향상시킴
LLM은 순차 추천에도 적용되었고, TALLRec, M6-Rec, PALR, P5 등이 있다.
더해서 ChatGPT 같은 것들은 explainable 추천을 생성함. 예시가 바로 Chat-Rec이고 ChatGPT를 이용해서 명확하고 이해가 되는 이유와 함께 추천을 해줘서 좀 더 신뢰와 사용자 참여를 촉진시킴.
더해서 interactive하고 대화가 되는 능력은 좀 더 dynamic 추천 경험을 제공한다.
UniCRS는 knowledge-enhanced prompt learning framework인데 대화와 추천 subtask를 만족시킴
UniMIND 또한 통합된 여러 multi-task learning framework이고, 이건 프롬프트 기반의 학습 전략을 대화형 추천 시스템에 사용해서 그렇다.
더해서 그래프를 학습하는데 LLM이 포텐셜이 있다. 두 가지 파이프라인이 존재함
LLMs-as-Enhancers: 노드 특성의 textual 정보를 향상
LLMs-as-Predictors: LLM이 link prediction problem 같은 그래프 학습에서 독립적인 predictor로 작용
그래프 기반의 추천을 하는데 있어서 가이드를 제공함
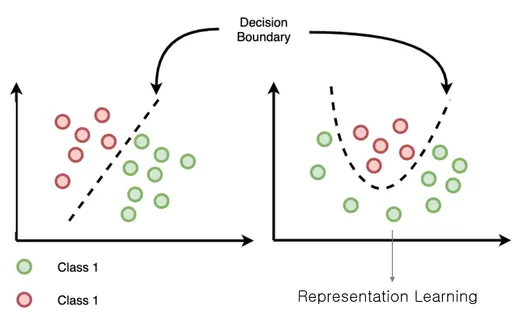
3. Deep Representation Learning for LLM Based Recommender Systems
유저와 아이템은 추천 시스템에서 atomic unit이다.
item과 유저를 나타내기 위해서 직관적인 방법은 unique index를 할당하는 것임
ID-based 추천 시스템은 사용자와 아이템의 reprsentation을 학습하는데 사용됨.
유저와 아이템에 대한 textual 정보들은 유저의 관심사에 대해 많은 정보를 준다.
end-to-end 훈련 방식에 있어서 user와 item의 representation learning을 향상시키는 목적으로 itextual side information recommendation method가 개발됨.
3.1 ID-based Recommender Systems
각 ID representation의 vector 임베딩을 학습함으로써 이런 행동들에 대한 모델을 하는 방향이다.
LLM 베이스 방법에서, P5라고 불리는 통합 패러다임이 다양한 추천 데이터 포맷을 전달하는 걸 가능하게 함.
user-item 상호작용, 유저 프로필, 아이템 설명, 유저 리뷰 등을 자연어 sequence 형태로 전달했고, 이건 유저와 아이템을 인덱스로 매핑해서 그렇다.
pre-trained T5가 P5를 personalized prompt로 훈련시키는데 사용됨. 한편, P5는 <item_667> 같은 형태로 인덱스를 처리했고, 여러 개의 토큰으로 프레이즈를 토크나이징 하는 걸 피했다.
이걸 기반으로 4가지 인덱싱 방식이 소개됨
1.
sequential indexing
2.
collaborative indexing
3.
semantic indexing
4.
hybrid indexing
Semantic ID는 각 user와 아이템에 대해서 semantic meaning을 가진 codword를 이용해서 ID를 만들었고, 특정 user나 item에 대해 semantic meaning을 가지도록 했다. 그 동안 이 codword를 만들기 위해서 RQ-VAE라는 계층적 방법이 제안되어서 semantic ID를 사용할 수 있게 되었고, 추천 데이터 포맷이 효과적으로 자연어 sequence로 바뀌었다.
3.2 Textual Side Information-enhanced Recommender Systems
ID-based 방식은 본질적인 한계가 있다.
pure ID 인덱싱은 기본적으로 이산적이라서, user와 아이템에 대한 표현을 잡아내기에 충분한 semantic information을 제공할 수 없다.
결과적으로 유사도 계산을 하는게 힘들고, user-item 상호작용이 엄청 sparse 함.
한편, ID 인덱싱은 주로 LLM의 파라미터 변경을 요구하므로 컴퓨팅 비용도 든다.
이런 것들 때문에, 대체 방안은 textual side에서의 정보를 이용하는 방법이다. 유저 프로필, 유저 리뷰, 아이템 제목이나 설명 등.
구체적으로 이런 정보들에 대해서 BERT 같은 LM 모델이 인코더로 동작할 수 있어서, 비슷한 아이템이나 사용자를 묶거나 좀 더 fine-grained granularity에서 차이점을 확인할 수도 있다.
ID와 modality-based 추천 시스템의 성능을 비교했는데, side information을 활용한 게 기존 ID-based를 challenge하고 있다고 밝힘
한편 Unisecc은 다양한 추천 시나리오에서 representation을 학습하기 위해 item 설명을 이용한 예시임. 구체적으로 Unisec은 경량 아이템 인코더를 소개하는데, 이건 parametric whitening 과 Mixture of experts를 사용한다.
문자 기반 CF는 또한 GPT-3 같은 LLM을 프롬프팅해서 연구됨
ID-base의 CF와 비교해서 TCF는 긍정적인 결과를 내놓았고, textual side 추천 시스템의 잠재력을 증명
아이템 설명은 인코드하는데 있어서 하나의 모델만 사용하는 것은 지나치게 text feature에 의존하는 것
VQ-Rec은 벡터 양자화 아이템 representation을 배우는데, 이건 item text를 이산적인 index의 벡터로 바꾸고 그걸 code embedding table에서 아이템 representation을 검색하는데 사용함.
text feature를 넘어서, Zero-Shot Item-based Recommendation을 제안했는데, 이건 Product Knowledge Graph를 LLM에 적용해서 아이템 feature를 refine하는 방법임. user,item 임베딩은 여러 pre-training 태스크를 통해 학습된다.
ShopperBERT는 구매 기록에 기반한 pre-training task를 통해서 사용자 임베딩을 pre-train한 recommender system에 있는 user representation을 나타내기 위해서 user behavior를 사용했다.
IDA-SR은 ID-agnostic User Behavior Pre-trianing framework for Sequential Recommendation,은 BERT 같은 LM을 이용해서 text 정보에서 representation을 얻는다.
item i와 이거에 대한 description이 m 토큰으로 되어있다면, 부수적인 start-of-sequence token이 Description 앞에다가 붙는다. 그래서 description이 LLM에 들어간다. 최종적으로 CLS에 대한 Token이 ID-agnostic item representation으로 사용된다.
4. Pre-training & Fine-tuning LLMs For RecSys
4.1 Pre-training Paradigm
모델 구조에 따라 두 가지 방식이 있다 1) masked language model 2) Next Token Prediction
•
MLM
◦
encoder-only 또는 encoder-decoder 트랜스포머 구조에 쓰임
◦
랜덤하게 토큰이나 span을 가리고, LLM에게 맞춰봐라라고 하는 거
•
NTP
◦
decoder-only 트랜스포머 구조, 그 다음에 올 token 맞추는 거
추천 시스템 맥락에서, 위 두 가지 전략을 따라간다. 대표적인 방법들을 몇 개 소개할 것
사례
PTUM
•
두 가지 비슷한 pre-training task를 제안함
•
Masked Behavior Prediction, Next K Behavior Prediction
◦
추천 시스템에서 유저 행동을 모델링 하기 위함
•
언어 토큰이랑은 다르게, 사용자 행동이 좀 더 diverse하고 그래서 좀 더 예측하기 어렵다.
•
MBP
◦
언어 모델이랑은 다르게, single user behavior를 마스킹하는데, 마스크된 행동을 다른 행동들을 기반으로 예측하는 것
•
NBP
◦
과거와 미래 행동의 relevance를 모델링하고, 이건 사용자 모델링에 중요함
◦
next k 행동을 히스토리로부터 예측하는 것
M6
•
pre-training 목적을 두 개의 classical pre-training task로부터 영감을 받아서 채택함.
•
text-infilling objective
◦
BART의 pre-training task를 나타냄.
◦
text sequence 상에서 몇 개 토큰을 랜덤하게 마스크하고, 예측하게 하는 것.
◦
text 또는 추천 스코어링 태스크에서 이벤트에서 plausibility를 평가하는 능력을 제공함.
•
auto-regressive language generation objective
◦
Next Token Prediction Task를 따름
◦
masked sequence를 기반으로 unmasked sentence를 유추해낸다는 점에서 약간 다르다.
P5
•
multi-mask modeling을 채택
•
다양한 추천 태스크의 데이터셋을 섞었다.
•
다양한 추천 태스크에 일반화되고, unseen task 또한 zero-shot generation ability로 일반화시킬 수 있다.
•
다른 추천 태스크와 다르게, P5는 통합된 indexing method를 언어 시퀀스 단에서 제공한다.
•
그래서 Masked Language Modeling task도 적용가능하다.
4.2 Fine-tuning Paradigm
추천 태스크에 한해서는 도메인 지식을 학습하는게 더 중요하다.
fine-tuning 패러다임은 task-specific 추천 데이터셋을 기반으로 pre-trained model를 훈련하는 걸 포함함.
이 데이터셋은 user-item interaction behavior나 side knowledge를 얘기함.
얼마나 파라미터가 바뀌냐로 두 가지로 나뉨
하나는 전부다 바꾸는 것이고, 하나는 일부만 수정하는 것
4.2.1 Full-model Fine-tuning
모든 파라미터를 바꾸는 것임.
RecLLM은 Conversational Recommender System으로써 LaMDA를 fine-tuning 한 것이다. 이건 유튜브 비디오 추천에 쓰임.
한편 GIRL은 지도학습 fine-tuning을 사용해서 LLM을 훈련 시켜서 job recommendation에 사용한다.
직접 fine-tuning을 하는 것은 RecSys에 의도하지 않은 bias를 가져옴. 이건 특정한 그룹 또는 민감한 속성을 가진 개인들에게 큰 피해를 준다.
이런 harmful한 거를 좀 완화하기 위해서, 간단한 LLM 기반 추천 시스템이 개발되었고, 이건 train-side masking과 테스트 단계에서의 비선호 엔티티의 중립화를 통해 편향을 완화하며, 이를 통해 중요한 성능 저하 없이 만족스러운 결과를 달성함
TransRec은 텍스트와 이미지를 섞은 형태의 아이템의 원시 특성에서 직접 학습, pre-trained 시스템을 end-to-end 연구. 겹치는 사용자나 아이템에 의존하지 않고, 다른 시나리오로 효과적으로 전화될 수 있음
추가적으로 차등 프라이버시를 적용한 대규모 RecSys를 이용해서 DP 훈련에서 과제와 제한을 완화함.
대조적 학습이 요즘 뜬다.
대조적 학습


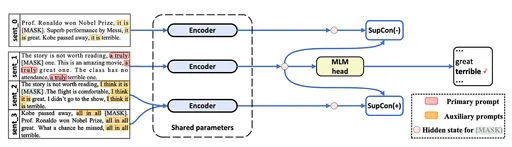

•
SBERT
◦
의도 문장과 관련 제품을 이커머스에서 긍정적 부정적 예시로 사용하여 모델을 훈련시키는 삼중 손실 함수를 사용
•
UniTRec
◦
차별화된 매칭 점수와 후보 텍스트의 혼란도(?)를 대조적 목표로 결합하는 통합 프레임워크를 제안
4.2.2 Parameter-efficient Fine-tuning
전체를 다 학습하기 힘드니까, 부분적으로 학습하는 방법이 PEFT이다.
PEFT에서 가장 좋은 방법은 adapter로써 추가적인 weight를 붙이는 것이다.
adapter 구조는 LLM의 트랜스포머 구조로 embedding하기 위해 디자인 됨.
각 트랜스포머층에서 adapter는 두 번 추가된다.
1.
multi-head attention 뒤에 projection 뒤에
2.
two feed-fowrard layer 뒤에
fine-tuning 동안, 원래 웨이트는 고정이고, adapter랑 정규화 layer는 downstream에 맞게 바뀜.
adapter는 catastrophic forgetting과 풀 파인 튜닝의 문제를 완화하면서 LLM을 일반화/확장함.
LoRA는 low-rank decomposition을 해서 수정해야할 차원을 줄임.
LLM의 기존 구조에서 matrix multiplication을 다루는 특정 모듈에 새로운 Path를 추가하는 것임.
두 개의 연속적인 행렬이 차원을 pre-defined된 dimension으로 줄였다가 다시 늘림.
중간 레이어의 차원은 intrinsic rank이다.
TallRec은 LLaMA-7B 모델과 LoRA를 이용해서 추천 task에 맞춰놓은 것으로 효과적이고 효율적인 것이고 RTX3090으로 돌아간다.
GLRec은 LoRA를 이용한 job recommender 이다.
M6는 LoRA를 이용했고, LLM을 모바일 기기에서 deploy하기 쉽게 바꿨다.
5. Prompting LLMs For RecSys
최근 paradigm이다.
LLM의 인풋으로 쓰이는 text template이다.
The relation between _ and _ is _ 라는 템플릿은 relation extraction task를 위한 것임.
이를 통해 언어 생성과 downstream의 목표를 일치하게 해준다.
ICL이나 CoT같은 기술도 광범위하게 조사되고 있음.
prompt tuning은 prompt token을 추가해서 task-specific recommendation dataset을 기반으로 업데이트 하는 방식
instruction tuning은 pre-trianing과 fine-tuning 패러다임을 prompting으로 합친 것인데, 이거는 LLM을 여러 추천 task에 instruction based prompt를 통해 fine-tune 한 것임. 이를 통해 zero-shot 능력을 향상시킴
5.1 Prompting
downstream task를 언어 생성 방식으로 풀어보려고 했음. (eg. text summarization, relation extraction, sentiment analysis).
이후 ICL이 등장.
CoT가 등장해서 LLM으로 하여금 복잡한 추론을 가능하게 함.
Conventional Prompting
•
두 가지 방법이 존재
◦
prompt engineering
▪
LLM이 pre-training 동안 마주한 프롬프트를 생성하는 것
▪
pre-trained language를 downstream task에 맞게 통합하는 것.
▪
Liu는 ChatGPT 프롬프팅을 해서 review summary task를 text summarization으로 하게끔 함.
•
Write a short sentence to summarize
◦
few-shot prompting
▪
몇 가지 예시를 줘서 LM을 가이드 하는 것.
언어 생성 태스크와 추천 태스크의 차이가 커서 별 효과를 보여주지 못했고, 일부 추천 태스크에만 사용됨.
•
리뷰 summary
•
item간 labeling 관계
In-Context Learning
Gao는 ICL의 성공을 두 가지 디자인으로 봤다; 프롬프트, 데모 예시
LLM이 downstream task를 배울 수 있도록, in-context 능력을 이끌어낸것.
두 가지 방식이 추천 시스템에서 많이 쓰임
1.
few-shot setting
a.
예시를 주고, 프롬프트로 제공된 downstream task를 완성하는 방식
b.
가장 직관적인 방법은 RecSys로 어떻게 하면 되는지를 LLM에게 알려주는 것
c.
Liu
i.
ChatGPT에게 여러 추천 태스크에 대한 설명을 제공해보았다.
ii.
top-K, rating prediction, explanation generation
iii.
user rating history를 넣어주고 rating prediction을 하는 식
iv.
다른 작업들도 각자만의 insight를 넣어서 데모를 진행했다.
1.
역할을 주입 - book rating expert - 해서 in-context 데모를 늘렸더니, LLM이 답변을 거부하는 것을 막을 수 있었음.
d.
RecSys로써 직접 가르치는 것 말고, LLM이 추천을 위한 external domain tool이나 전통적인 RecSys를 부르는 걸 할 수 있었음.
i.
Chat-Rec은 traditional RecSys와 ChatGPT를 연결하는데, RecSys에서 나온 후보군들을 ChatGPT가 추린다.
ii.
Zhang
1.
외부 graph reasoning tool을 위한 API call template을 디자인해서 ChatGPT로 하여금 template을 써서 graph-based recommendation 결과를 만들어내는 데 성공
2.
zero-shot setting
a.
데모가 없고, 자연어 설명으로만 태스크를 설명함.
b.
성능에 감소가 있어도, zero-shot은 task-specific 추천 데이터셋을 만들지 않아도 되고, 대화형 추천 같은 task에는 유용할 수도 있다. - 데모를 넣는 것에 익숙하지 않은 사람들을 위해 -
i.
Wang
1.
ChatGPT로 하여금 대화형 추천을 하도록 zero-shot template을 제공했고, 이건 두 가지로 나뉘어져있음.
2.
대화형 추천 태스크에 대한 설명과 format
a.
format은 아웃풋을 parsing하기 쉽게 만들어줬음.
Chain-of-Thought Prompting
In-context example을 통해서 프롬프팅하는 건, 몇 가지 추론 단계를 요구해서 답변하기에 어려울 수 있음.
이를 통해서 몇 가지 추론 단계를 빼먹어서 잘못된 추론 로직을 가져서 에러가 날 수 있음.
비슷한 multi-step 문제가 RecSys에 있는데, 대화형 추천에서 multi-turn dialogue를 통해 사용자의 기호를 추론하는 것 등이 해당 문제임.
zero-shot CoT
Let’s think step by step으로 한다던가, Therefore the answer is 라는 문장을 프롬프트에 넣으면 LLM은 task-specific한 추론 과정을 알아서 밟는다.
Few-shot CoT
ICL에서 input-output 데모가 input-CoT-ouput 방식으로 바뀜.
각 스텝별로 설명을 해야하기 때문에 데모의 양이 늘어난다.
실제로는 CoT 스텝은 컨텍스트와 추천 태스크의 목적에 많이 의존함.
please infer the preference of the user and recommend suitable item은 LLM이 처음에 유저의 기호를 추론하고 최종 추천을 하게 함. CoT를 활용한 추천 관련 연구는 많이 없는 편이다.
CoT Prompting
추천에서 아직 CoT가 많이 없지만, 최근 연구는 추론 단계를 node로 하고, 추론 path를 edge로 해서 LLM의 그래프 추론 능력을 촉진하는데 CoT 프롬프팅을 채택함.
비슷한 아이디어가 RecSys에도 적용될 수 있을 것이라 생각하고, 추천 시스템에 link prediction 문제의 특별한 예시로 생각하면 가능하지 않을까 싶음.
5.2 Prompt Tuning
manually하게 하는 것보다, 프롬프트 토큰을 더해서 프롬프트를 task-specific dataset 기반의 프롬프트로 최적화 시킴.
일반적으로 task-specific 지식과 노력이 덜 들며 tunable prompt과 LLM의 인풋 레이어의 약간의 파라미터 수정을 요함.
•
AutoPrompt
◦
prompt를 여러 단어 토큰으로 자르고, gradient-based search를 통해 LM에 가장 적합한 토큰을 찾아서 특정 태스크에 최적화된 성능을 내고자 함.
프롬프트는 discrete 하거나 continuous 일 수 있는데, 이 두 가지로 나눠서 얘기를 할 거임.
Hard Prompt Tuning
•
Dong
◦
ICL은 hard prompt tuning의 subclass로 간주할 수 있다.
◦
ICL의 데모 또한 Prompt의 일부로 생각할 수 있다.
discrete optimization 문제에 부딪힌다. 노동집약적인 시도와 에러를 통해서 적절한 프롬프트를 찾아야하기 때문.
Soft Prompt Tuning
prompt로써 text embedding 같은 continuous vector를 사용하고, prompt를 task-specific dataset을 기반으로 최적화한다. 예를 들어 프롬프트를 recommendation loss를 기반으로 업데이트한다던지.
input layer에 있는 original input token에 prompt token을 붙이는 방식인데, 이 과정에서 soft prompt와 input layer의 최소 파라미터가 수정됨.
특성 추출과 표현 학습 기법을 결합해서 task-specific 정보를 잘 캡처해서 soft prompt에 embed 시키려고 한다.
•
Wu
◦
대조적 학습을 사용해서 user representation을 잘 캡처하고 그걸 prompt token에 인코드한다.
•
Wang, Guo
◦
mutual information을 인코딩해서 soft 프롬프트에 넣는 아이디어를 공유함.
◦
서로 다른 도메인 간의 관련성이나 연관 정보를 포착하여 추천 시스템의 성능을 향상시킴.
태스크에 대한 정보를 soft-prompt에 넣는 것이 아니라 task-specific dataset으로부터 학습할 수도 있음.
•
무작위로 초기화된 soft-prompt가 T5가 원하는 추천 결과를 내도록 가이드함.
◦
end-to-end 방식으로 soft prompt가 최적화되고, 이건 T5가 내는 추천 loss를 기반으로 업데이트 됨.
hard 보다는 최적화하기가 continuous space에서 일어나니까 쉽지만, 읽기 어렵다.
5.3 Instruction Tuning
프롬프팅 전략을 사용할 때, zero-shot은 별로 좋지 않음.
이런 한계점을 해결하기 위해, 다중 프롬프트를 통해 LLM을 fine-tune하는 방식이 제안됨.
이 방식은, prompting, pre-training, fine-tuning 패러다임의 특징을 모두 가지고 있음.
task를 위한 instruction을 정확히 따르는 능력을 LLM에게 줌으로써, zero-shot 능력을 향상시킴.
구체적인 downstream task를 해결하는 것이 아닌, task instruction을 정확히 따르는 것처럼 프롬프트를 줘서 훈련시키는 것임.
instruction 생성 단계와 model tuning 단계로 나뉘어지는데, 이것은 직관적으로 프롬프팅과 fine-tuning의 조합임.
Instruction Generation Stage
자연어로 이루어진 지시사항 베이스의 프롬프트이고, 이건 task-oriented input과 원하는 target 쌍으로 이루어져있다.
Zhang
•
추천 기반 Instruction 템플릿을 제공했는데, 이건 user preference, intention과 다양한 추천 태스크를 위한 instruction을 생성하는 일반적인 템플릿을 포함함.
•
task description-inpput-ouput의 형태로, task-specific 추천 데이터셋을 기반으로 지시를 작성함.
Model Tuning stage
LLM을 fine-tuning 하는 방식이 여기에 똑같이 적용된다.
Bao
•
LoRA를 사용해서 instruction tuning을 진행했고 좀 더 lightweight 하게 진행함.
LLM의 그래프 이해 능력을 향상시키기 위해 instruction tuning이 사용됨.
Wu
•
LLM-based 프롬프터 생성기
•
행동 그래프 안에 있는 node(후보 아이템)의 경로와 edge(아이템 간 관계)를 자연어 표현으로 바꿔줘서 LLM-based 추천 시스템에 instruction tuning으로 사용할 수 있음.
6. Future Directions
6.1 Hallucination Mitigation
헛소리하는 것
문제의 원인은 다양한데, source-reference의 불일치, 훈련&모델링 선택 등임.
고위험의 추천을 할 수 있다. 약이나 법적 조언 등
이 문제를 해결하기 위해 사실 기반 그래프를 부가적으로 훈련이나 추론 단계에 적용하면 조금 해결될 수 있지 않을까 싶고, 모델의 아웃풋 도한 엄격하게 검토가 되어야함.
6.2 Trustworthy LLM for RecSys
믿을 수 없는 decision making, 투명성과 설명성에 대한 부족, 프라이버시 문제 등등.
신뢰가 있는 LLM-based RecSys를 만들기는 어렵다.
•
Safety&Robustness
◦
인풋 값에 작은 변화, 특히 적대적인 변화에 취약함
◦
safety-critical application에 사용될 수도 있음
◦
악의적인 목적으로 noisy input을 넣을 수도 있는 노릇임.
◦
GPT-4는 safety-related prompt를 reinforcement learning from human feedback을 할 때 집어넣음.
◦
RLHF는 manual labeling이 필요해서, 실제로는 가능하지 않을 수도.
◦
대안은 자동으로 프롬프트에 대해 pre-processing을 거치는 것이다.
▪
같은 final input을 하기 위한 표준화나 malicious prompt를 막는 역할을 함.
◦
adversarial training이 LLM 기반 RecSys의 robustness를 향상시키는 방법임.
•
Non-discrimination&Fairness
◦
차별이나 편견을 반영한 추천을 한다.
◦
아이템이 공정하지 못하게 추천되거나 추천이 안 되거나 할 수 있음
◦
FiaRLLM이나 UP5 같은 연구가 추천 시스템의 공정성 문제를 탐구함.
▪
user-side나 item 생성 태스크에만 집중함
◦
Hou
▪
조건적 랭킹 태스크로 인식하게 해서 item-side 고정성을 높임.
•
Explainability
◦
privacy, security와 관련해서 ChatGPT, GPT-4 같은 애들은 오픈소스가 아니다.
◦
LLM 기반 RecSys는 블랙박스이다.
◦
왜 결과가 나왔는지 알 수 없음.
◦
Bill은 GPT-4로 하여금 GPT-2 모델의 neuronal behavior을 설명하게 했다.
◦
어떻게 LLM이 추천에서 동작하는지, 설명력을 높이는 것이 필요
•
Privacy.
◦
여러 데이터 소스를 통해 LLM을 만들었고, 그래서 개인 정보가 포함되었을 수 있으며 개인정보 유출이 있을 수 있다.
◦
그리고 이건 사용자 행동이나, 민감한 정보나 이런 것들을 가질 수 있다.
◦
이런 걸 잘 보호하는 건 중요하다.
◦
text를 생성할 때, 실제 정보를 뱉을 수 있다.
6.3 Vertical Domain-specific LLM for RecSys
Medical care, Law, Finance 쪽 지식에 확실히 이해가 깊은 애들을 만들 수 있을 것임.
domain-specific data가 많이 필요하겠지만
좋은 품질을 많이 모으고, 적절한 튜닝 기법을 사용하는게 이런 걸 만들 수 있는 방법임.
Jin
•
Amazon-M2 데이터셋이라고 이름 붙은 여러 언어 데이터셋을 제안
•
Amazon의 세션 베이스 추천을 위한 세팅.
•
session graph와 text 데이터를 LLM이 학습하는데 이용함.
•
item은 노드로써 title, price, description을 포함함.
◦
다른 로케일에 있는 유저의 세션 그래프 상에서의 설명도 포함
6.4 User&Item Indexing
긴 텍스트를 다루기 어려움.
user-item interaction 정보를 긴 글에서 찾아내기가 힘듬
ID가 있는 user-item 인터렉션은 많은 정보를 가지고 있고, 사용자 기호를 이해하고 예측하는데 도움을 준다.
이 인터렉션은 명시적인거랑 암시적인거 모두 포함함.
InstructRec, PALR, GPT4Rec, UP5는 user-item 인터렉션 기록 정보를 LLM에 텍스트로 넣어서 추천을 한 것임. 긴 텍스트 문제를 해결하기 위해 한 가지 방법은 user-item indexing을 하는 것임.
user-item을 표현하는데 text format을 사용하는 것보다, user-item을 인덱싱하는 발전된 방법이 훨씬 좋다.
6.5 Fine-tuning Efficiency
Fine-tuning을 효과적으로 하는게 중요함.
Fu
•
어댑터 모듈을 사용해서, 작은 플러그인 뉴럴넷으로 파라미터 효과적인 전이 학습을 할 수 있음
크로스-플랫폼 이미지 추천에 대해서는 fine-tuning 모델보다 살짝 안 좋다.
multi-modal RecSys에서 어댑터 튜닝은 기회임.
가장 전형적인 adapter tuning은 실제로 훈련 과정을 빠르게 하지 못하는데, computation cost와 시간을 End-to-End 훈련으로 줄이는 방법이 중요함.
6.6 Data Augmentation
data-driven research로 진행됨. 보통 디지털 플랫폼에서 사용자 행동 데이터를 모은 것을 기반으로 해서 하거나 annotator 모집해서 한다.
그럼에도 불구하고 resource-intensive한 건 맞고, long-term으로 하기에는 무리가 있다.
모델의 성능과 다양성에 데이터가 바로 영향을 끼침. 이런 실제 데이터 중심 연구에서 벗어나고자 함.
Wang
•
RecAgent
◦
시뮬레이션 패러다임이다.
◦
유저 모듈
▪
소셜 미디어의 대화나 브라우징하는 모델
◦
추천 모듈
▪
search 또는 추천 리스트를 제공함
•
LLM-Rec
◦
4가지 프롬프팅 전략을 포함함.
◦
프롬프트를 다양하게 하는 방법이랑 input augmentation 기술이 추천 성능을 높임.
그냥 배포하는 것보다, data augmentation을 해서 추천 능력을 올린 다음에 배포하는게 좋을 듯
7. Conclusion
LLM은 언어 이해와 생성에 능하고, 강력한 추론과 일반화능력, 새로운 도메인에서 prompt-adaption이 가능함.