
Abstract
user-item 관계를 DNN과 뉴럴넷으로 잡아냄으로써, 추천 시스템은 많은 발전을 이룸.
기존 방법은 ID-based이고, 그래서 텍스트 정보를 반영하지 못한다.
implicit interaction을 활용하는 건 noise랑 bias를 가지고 있어서, 소비자 기호를 학습하는데 힘들다.
LLM이랑 기존 추천 시스템 결합은 1) text에만 의존적인 상황 2) scalability 이슈 3) 프롬프트 인풋 등.
LLM 기반의 표현학습을 합쳐서 기존 추천 시스템을 향상시킨다. 사용자 행동이나 기호적인 측면에서 복잡한 의미를 뽑아냄.
RLMRec은 사용자의 행동과 선호도의 복잡한 의미적 측면을 포착할 수 있도록 LLM을 활용하여 사용자/아이템 프로필링을 수행하고, 협업 관계 신호와 LLM의 의미 공간을 교차 뷰 정렬을 통해 일치시킵니다.
이를 위해 학문적 기초도 제공하고, noise data에 대한 efficiency와 robustness를 분석함.
Introduction
딥러닝 및 GNN이 추천시스템에 많이 쓰였고, NGCF, LightGCN이 SOTA에 올랐다.
ID로만 봐서, 다른 텍스트 데이터를 간과하고, representation에서 정보 부족에 시달린다.
implicit feedback을 포함한 그래프는 noise를 많이 발생시킨다.
결과적으로 학습된 표현력은 data의 퀄리티에 많이 의존한다. 이런 의존은 표현력에 저해를 가져올 수도 있고, 결국 추천 시스템의 효과성을 저해함. 특히 데이터에 노이즈가 많을 때
LLM을 이용한 시도는
1.
프롬프트 디자인으로 언어모델과 추천을 일치시키는 것
a.
InstructRect는 추천 작업을 instruction-question-answer 구조로 구조화해서 LLM이 추천을 다룰 수 있고 정교한 질문에 답을 하도록 구성됨.
b.
기존 모델들보다 efficiency랑 precision에서 뒤떨어진다.
c.
접근 자체에서 오는 단점들로부터 기인함.
해당 접근의 단점
•
유저 행동 데이터가 사이즈가 커지면서, 컴퓨팅 비용과 시간이 많이 든다.
◦
TALLRec은 instruction-question-answering format을 기반으로하는데, LLaMA2-13B 응답에 대해 3.6초 응답 시간이 걸림; input token이 800개 일때
◦
이건 엄청 많은 유저와 아이템 카탈로그를 다루는 추천시스템을 위한 접근으로는 쉽지 않은 방법이다.
•
text 의존성에 기인하는 한계
◦
Hallucination 때문에 없는 아이템을 추천해줄 수도 있다.
◦
답변의 정확성과 신뢰성을 보장하지 못함.
◦
제한된 프롬프트 인풋은 전체 사용자의 의존성을 반영하는 시그널들을 모델링하기 힘들 수 있다.
이것을 증명하기 위해, LLM을 이용해서 아마존 데이터셋 추천을 위한 re-ranking task를 진행했다.
ChatGPT로 진행됬고, 이 실험은 각 유저에 대해서 top-10&20 개의 아이템을 re-ranking 하는 것임
실험 결과는 원래 LightGCN으로 제공되는 것보다 훨씬 낮음.
이건 세 가지 이유 때문인 것 같은데,
1) hallucination 이슈 2) input token limit으로 인해 global text-based collaborative relationship을 잘 잡지 못한다는 것 3) 추가적으로, large-scale 데이터에 대해서 몇 시간 씩 걸린다는 것.
RLMRec의 핵심 아이디어는 ID-based 추천과 LLM간의 다리 역할로서 representation learning을 사용하자!
기존 추천 시스템의 정확도나 효율성은 유지하면서 강력한 텍스트 이해 능력을 이용해서 사용자 행동과 기호의 복잡한 의미를 이해하는 것임.
설명,리뷰,태그 등의 텍스트 정보를 특성을 잘 반영한 벡터 형태로 만드는 과정을 포함하며, 텍스트 기반 표현과 user/item 상호작용을 통해 얻어지는 정보 공유를 최대한으로 하고자 함.
user/item 프로파일링을 LLM을 통해서 할 것이며, LLM의 지식 하에서 포괄적인 의미를 포함함으로써 표현력을 높이고자 함.
LLM의 의미 공간과 여러 관계 시그널의 표현 정보를 cross-veiw alignment framework를 이용해서 일치시키려고 함. 이 일치는 cross-view mutual information maximization scheme을 통해서 이뤄질 것
이를 통해 텍스트와 협업 관계 임베딩이 각각 대조적/생성적 모델을 통해 잘 정렬된 공통 의미 공간을 찾음.
•
LLM을 이용하고 collaborative relation 모델링과 LLM의 의미 공간을 잘 일치시킴으로써 기존 추천 시스템을 뛰어넘는 방법을 연구
•
RLMRec을 제안하고, 대조적 또는 생성적 모델링 기법을 이용해서 표현 퀄리티를 높임
•
textual signal을 활용하는 게 표현 학습을 향상시킨다는 이론적 기반을 마련함. mutual information maximization을 이용하여, 어떻게 텍스트 시그널이 표현 퀄리티를 높이는지 보여줄거임
•
RMLRec을 SOTA 추천 모델에 결합하고, 효과성을 볼거임. 추가적으로 noise와 완전치 않은 데이터에 대한 robustness를 분석하고, real-world challenge를 다룰 수 있을지 볼거임.
Related Work
GNN-enhanced Collaborative Filtering.
협업 필터링은 사용자-아이템 상호작용을 바탕으로 아이템을 추천하는 기술임.
최근 뜨는 방식은 historical 상호작용을 이용해서 bipartite graph를 만들고, GNN을 이용해서 고차원의 관계성을 잡아내는 것임. 이런 것에는 NGCF, GCCF, LightGCN이 있음
implicit data에 들어있는 sparsity와 noise가 문제임. self-supervised learning을 부가적인 학습 목적으로 사용해서 robustnes를 향상시킴. 다양한 SSL 기법들 중, 대조적 학습이 뜨고 있다. SGL, SimGCl, NCL, LightGCL 등은 대조적 데이터 augmentation을 이용해서 추천 능력을 향상시킴.
여기서는 LLM을 기존 CF 모델에 합쳐서 LLM의 지식과 추론 능력을 collaborative relation learning과 일치시켜보려고 함.
Large Language Models for Recommendation
프롬프트를 추천 태스크에 맞게 잘 디자인하는 식임.
P5는 interaction 데이터를 text prompt로 바꿔서 언어 모델 훈련에 사용함.
Chat-REC은 사용자 프로필과 인터렉션을 프롬프트로 바꿔서 대화형 추천을 함.
InstructRec과 TALLRec은 추천 태스크를 정의하는 지시어 디자인을 해서 LLM을 파인튜닝함.
LLM을 바로 추천 생성에 사용하는 것은 컴퓨팅 비용과 느린 추론 시간으로 무리가 있음. 이런 점에서, mutual information maximization을 채택해서 LLM의 지식과 collaborative relation modeling을 결합함으로써, scalable하고 효과적인 추천을 하게 함.
3. Methodology
3.1 Theoretical Basis
Collaborative Filtering
•
u, v가 각각 사용자와 아이템이라고 하자.
•
e가 representation이다.
•
초기 임베딩은 x임
•
상호작용은 X임
우리는 초기 임베딩이 주어졌을 때, 나중에 e가 나올 확률을 높이는 것임.
여기서 상호작용은 false positive와 false negative 두 개를 포함한다. 학습된 e는 노이즈에 영향을 받음. hidden prior belief z는 추천에 용이하다. 이건 X에서 positive sample을 잘 규정함.
표현 e를 생성하는 것은 z와 피할 수 없는 노이즈의 조합을 포함함.
Text-enhanced User Preference Learning
표현과 상관없는 시그널들을 무시하기 위해서, 부가적인 정보를 포함하는 것이 필요함.
textual information이 그 방법 중 하나임. eg. user, item profile,
이런 텍스트 정보는 s라고 하는 표현을 생성하는 language model을 통해 인코딩 된다.
s랑 e는 공유하고 있는 정보를 capture한다. 이 정보들이 추천에 용이하고, 이게 바로 prior belief z이랑 align되는 것임.
추천에 도움이 되는 z라고 하는 것에서 파생된 recommendation-beneficial 한 정보를 담고 있는, e와 s를 가지고, optimal한 값인 e*를 학습하는 것이다. 다음과 같은 conditional probability를 최대화해서
이건 암시적으로, e가 z로부터 파생된 정보를 가지고 있고 s와 관련된 정보를 통합하게끔 한다.
이 식은 e,s를 알 고 있을 때, z에 대한 확률을 극대화하는 e를 찾는 것을 목표로 함.
우변에 있는 함수는 Theorem 1에 의해서 Mutual Information 으로 바뀜.
Theorem2는 Mutual Information을 최대화하는 것은 특정한 Lower bound를 maximizing하는 것임.
⇒ mutual information을 유지하는데에 density ratio를 도입함.
결과적으로 도출되는 식은 외부 정보를 이용해서 어떻게 noisy effect를 줄일 수 있는가를 보여줌.
1.
user, item에 대해서 어떻게 효과적인 설명을 얻을 것잉ㄴ지
2.
e와 s 사이에 mutual information을 극대화하기 위해서 density ratio를 효과적으로 모델링하는 법을 어떻게 포함할 것인지
3.2 User/Item Profiling Paradigm
•
User Profile
◦
user가 선호하는 특정 타입의 아이템이 포함되어있어야함. 그들의 개인화된 취향의 포괄적인 표현할 수 있는
•
Item Profile
◦
아이템이 atract해보이는 분명한 타입의 user들이 있어야함.
◦
해당 유저들의 선호나 interest와 일치하는 item의 특성이나 퀄리티의 표현이 잘 되야함.
유저는 리뷰를 남기고, 아이템은 장소와 카테고리를 포함함.
이런 텍스트 데이터는 어마어마한 노이즈를 남길 수 있음.
1.
Missing Attributes
a.
어떤 아이템이나 유저의 특성이 없을 수 있음.
2.
Noisy Textual Data
a.
텍스트 그 자체로 노이즈 과다로 오염됬을 수 있음. 해당 노이즈는 사용자의 기호와 상관없기에 발생하는 것
b.
Stream dataset에서, 게임에 대한 유저 리뷰는 다양한 special symbol이나 관련없는 정보를 포함할 수 있음
c.
이런 것들이 어려워서, 대부분의 모델은 semantic information을 이용하지 않고 noise가 적은 특성만 one-hot encoding으로 변환함.
운좋게 LLM을 통해서 text denoising과 summarizing이 가능해짐.
이를 통해 profile generation을 해서 collaborative information으로 활용할 것임
데이터셋이 주로 유저에 대한 특성보다 아이템에 대한 특성이 더 많기에, 우리는 item-to-user 관점을 취할 것임
Profile generation via Reasoning
LLM을 통해 Prompt Q를 넣고 Profile을 생성함.
Item Prompt Construction
아이템에 대해서 title alpha, original description beta, dataset-specific attribute인 gamma
그리고 n명의 유저로부터 모아진 리뷰 n개. 4가지 텍스트 정보로 분류함.
설명이 있다면, [제목, 설명]만 하고, 없으면 [제목, 부가 설명, 리뷰]로 하는데, 이 때 리뷰는 랜덤하게 함.
함수 f_v를 쓸건데, 이거는 여러 텍스트 feature를 하나의 문자열로 바꿔주는 역할임.
User Prompt Construction
유저 프로필을 만들기 위해 collaborative 정보를 사용할 거임. 우리가 이미 item profile을 만들었다는 가정 하에.
구체적으로 I_u로써 user u와 아이템이 인터랙션 했다고 생각하고, 그 중 subset을 뽑아낼 것임.
샘플링된 것들 중 각 아이템에 대해서, 우리는 텍스트 특성을 concat할 것임. c_v = [ 제목, P_v. r_u_v] 이런 식.
r_u_v는 v에 대해 u가 남긴 리뷰.
인풋 프롬프트 Q_u는 다음과 같이 정의됨.
function에다가 c_v가 들어가는데 이 함수는 논리정연한 string으로 만들어주는 함수임.
3.3 Density Ratio Modeling for Mutual Information Maximization
density ratio를 모델링하는 방법에 대해 얘기할 거임
mutual information을 극대화하는데 초점을 맞추는게 density ratio 임
s_u는 P_u를 텍스트 임베딩 모델에 넣어서 나온 결과값임.
density ratio는 s와 e에 대해서 유사도를 측정하는 양의 점수로 간주할 수 있음.
2가지 모델링 방법을 소개함
1.
contrastive modeling
a.
밀고 당기는 방식으로 이미 검증된 방법
2.
mask-reconstruction generative modeling
a.
self-supervised 메커니즘으로서 많이 쓰이고, masked input을 스스로 채우는 방법임
Contrastive Alignment
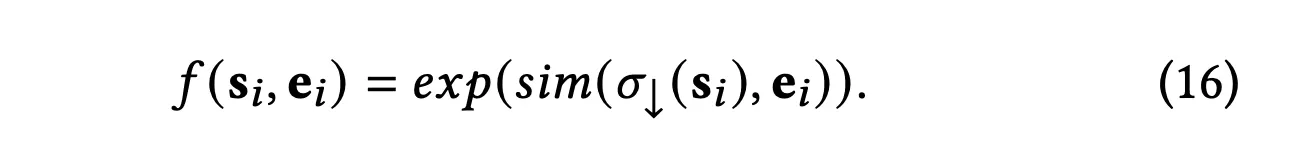
sim은 cosine similarity임. sigma_down은 multi-layer perceptron이고, s를 e의 특성 공간으로 바꿔주는 것임. e와 s를 양의 샘플로 둔다.
학습과정동안, 이 쌍들은 서로 밀고 당겨지면서 그들의 표현을 정렬함.
구체적인 구현으로, positive sample pair들은 모으고, 나머지들은 negative로 생각함.
Generative Alignment
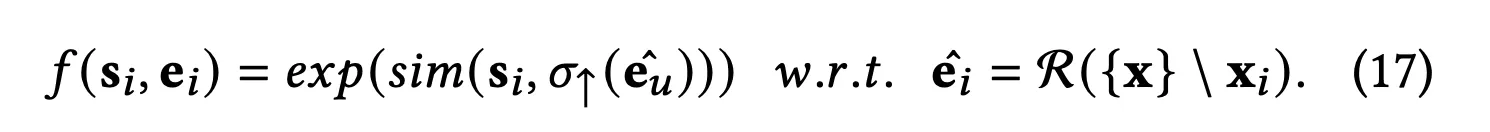
masked autoencoder에서 영감을 얻어서, MAE 안에서 density ratio를 모델링하는 접근을 함.
representation을 semantic feature space로 먼저 perceptron model이 mapping을 함.
i번째 sample에서 masking을 적용한 거를 그럼 semantic으로 mapping하는 것.
masked sample에 대해서 semantic representation을 다시 만드는 것임.
3.4 Model-agnostic Learning
이 지점까지, 우리는 CF-side 관계 표현인 e와 LLM-side 의미 표현인 s를 어떻게 최적화할 것인지 논의함.
어떤 모델이든 앞의 최적화 과정을 거칠 수 있음.
Recommender R에 대해서 objective가 L_R이라고 하면 최종적인 L은 L_R에다가 L_info를 더 한 것임
L_info는 앞에서본 I(si,ei) 값임.
4. Evaluation
4.1 Experimental Settings
4.2 Performance Comparison
4.3 Ablation Study
4.4 In-depth Analysis of RLMRec
Conclusion
모델에 종속되지 않은 RMLRec을 소개하고, LLM을 이용해서 추천 시스템의 표현력을 향상시킴.
collaborative 프로필 생성과 추론 과정을 강조하는 reasoning-driven system prompt를 제안함.
대조적 바식 또는 생성적 방식을 사용해서 CF 기반 관계 embedding과 LLM 기반 의미 표현을 합침.
이 프레임워크는 일반적인 Rec과 LLM의 강점을 결합하고, 이론적인 근거로 지지하고, real-world dataset을 기반으로 평가했음. LLM 기반 추천에서 설명력을 높이는 방식으로 연구를 진행할 예정