.jpg&blockId=1b87074d-017e-8069-9667-d5678d39e51d)

데이터 저장에 디스크가 어떻게 쓰이는지 살펴보자.
데이터는 record로 표현이 되고, 이건 disk block 안에서 consecutive bytes를 구성한다.
relation 같은 collection은 하나 또는 여러 블럭을 나타내는 레코드를 적절히 배치는 것을 말함.
Fixed length Records
fields: 튜플의 하나의 속성을 나타내는 것
헤더로 시작을 한다. 고정된 영역이고 레코드에 대한 정보를 저장함
•
스키마에 대한 포인터
•
레코드 길이
•
언제 수정되었는지 time stamp

Fixed length record를 block에 packing하기
•
block 안에 끼워넣어지는데, 이 때 header가 필요함
•
헤더
◦
다른 블럭에 대한 link
◦
속한 relation에 대한 정보
◦
block안에서 각 record에 대한 offset을 제공하는 directory
◦
수정 및 접근 timestamp
Representing Block and Record Address
메인 메모리에 있을 때, block의 주소는 그것의 첫 바이트 virtual memory 주소이고, record의 주소는 그 레코드 첫 바이트의 메모리 주소이다. 하지만, secondary storage에서, block은 application의 virtual memory address space의 주소가 아니다. 이에 더해서, 바이트 sequence는 전체 시스템에서 접근 가능한 위치를 나타낸다.
각 레코드는 block address에 각 레코드의 offset으로 식별된다.
•
client-server
•
주소 표현을 위한 다양한 옵션
•
pointer swizzling
Address in client-server systems
client의 경우에 데이터를 쓰는 쪽이고
server의 경우에 데이터를 저장하는 쪽이다.
client는 virtual address space를 사용한다. 32비트 짜리인.
OS는 address space의 어떤 부분이 main memory에 있는지 결정하고, 하드웨어가 virtual address space를 physical location에 매핑한다.
서버의 데이터는 database address space에 있다.
이건 block을 참조하고, 블럭 안에 있는 offset도 참조한다.
이를 표현하는 방법에는 여러 개가 있는데, physical address 이거나 logical address가 있다.
logical and structured Address
•
logical address를 쓰면 결국 physical address랑 매핑하는 매핑테이블을 만들어야하는데, 이런 경우에 무슨 장점이 있느냐고 얘기할 수 있다.
•
꽤 considerable한 장점이 있는데, 그건 바로 flexible하게 move할 수 있다는 것
•
이런 map table에 대해서, 우리는 모든 레코드를 매핑할 수 있고, 따라서 그저 table에 있는 행들을 바꾸는 것만으로도 동일한 효과를 낼 수 있다.
logical 과 physical address를 같이 쓰는 방식은 여러개가 있다. 예를 들면 structured address scheme.
•
physical address로 블럭을 특정하고, 특정한 key 값으로 record를 특정하게 해도 된다. 이러면 block까지는 physcial address로 찾아가고, 레코드의 경우에는 적절한 키로 블럭 안에서 찾으면 된다.
•
또 다른 방법은 블럭 안에 각 record에 대한 offset을 기록하는 것이다.
◦
이 방법은 record가 같은 size가 아닐 때 유용함.
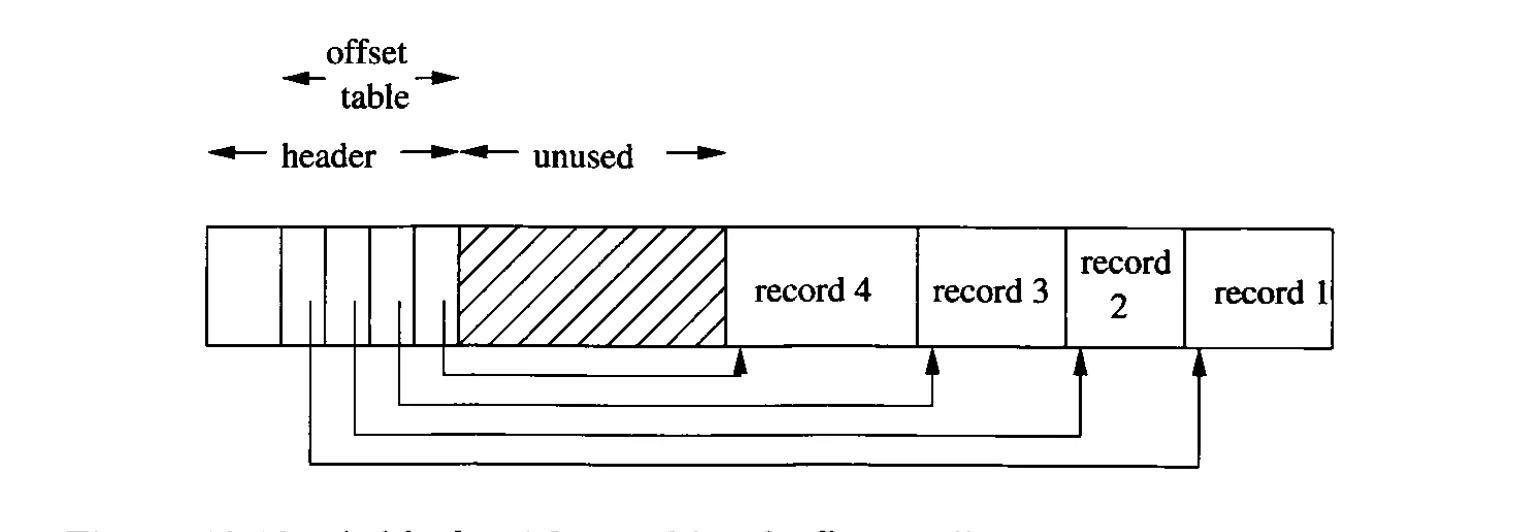
•
record의 주소는 이제 블럭의 physical address 주소에다가 각 레코드의 offset을 더한 것이다.
•
이 정도 수준의 indrection은 다양한 장점이 있다.
◦
block 안에서 record를 움직일 수 있고, 우리가 할 건 record’s entry를 바꾸는 것 뿐이다.
◦
record를 다른 블럭으로 옮기는게 가능하다. 만약 offset table이 옮겨진 새로운 주소를 가리키는 forwarding address를 가질만큼 크다면
◦
마지막 옵션은, 레코드가 삭제되었을 때, offset table에 비석을 세우는 것이다.
▪
특정한 값으로써, 레코드가 삭제되었음을 알려주는 것
▪
deletion에 비해서, 이 레코드에 대한 포인터는 다양한 곳에 저장될 수 있다.
▪
그래서 포인터는 null pointer로 대체될 수 있다 → 렉노 보면 옵션에 따라 다 바뀌어 있다.
Pointer Swizzling
Table map이 logical address → Database address로 바꿔주는 것이다.
이건 어쨌든 물리 주소에 대한 aliasing이고, 디스크 이내의 모든 주소에 대해서 다 포함한다.
하지만 disk에서 메모리로 record를 가져올 때, physical memory에서 virtual memory로 매핑해주는게 필요하다. 이것이 translation table
이 때 특정 레코드에서 다른 레코드로 포인터를 가지고 있다면, repeating하게 되는 문제가 생긴다.

위 상황에서 같은 block에 있는 record를 참조하는 pointer가 있을 때, 이걸 swizzled하지 않는다면, 이건 여전히 database address를 가리키고 있어야할 것이고, 따라서 메모리에서 메모리로 바로 연결을 못하게 된다. 매번 참조할 때마다, translation table에 가서 메인 메모리 주소를 얻어와야하기 때문에, 옮길 때부터 값을 바꿔버리는게 swizzling
Variable-Length Fields
•
데이터 아이템의 사이즈가 바뀌는 것: address field의 사이즈가 바뀌는 경우
•
repeating fields: many-many relation을 나타내기 위해서, 해당 object와 관련되있는 레퍼런스들을 저장한다.
•
variable format record: 레코드의 필드가 뭐가 될지 모르고, 얼마나 나타날지도 잘 모를 수 있다.
•
Enormous fields: attribute의 값이 엄청 큰 경우, MPEG 등등
1.
Records with Variable Length field
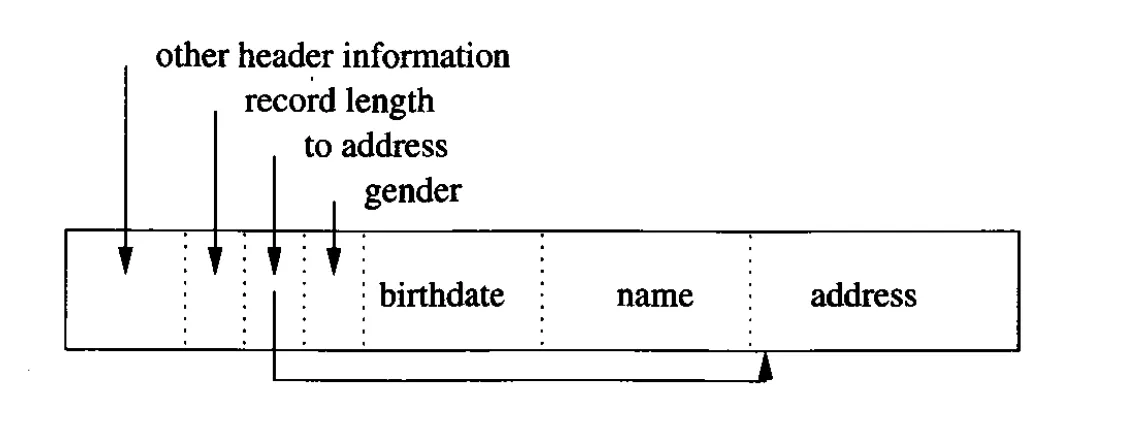
•
이런 식으로 variable length 에 대해서 pointer를 가지고 있다.
2.
Records with repeating fields
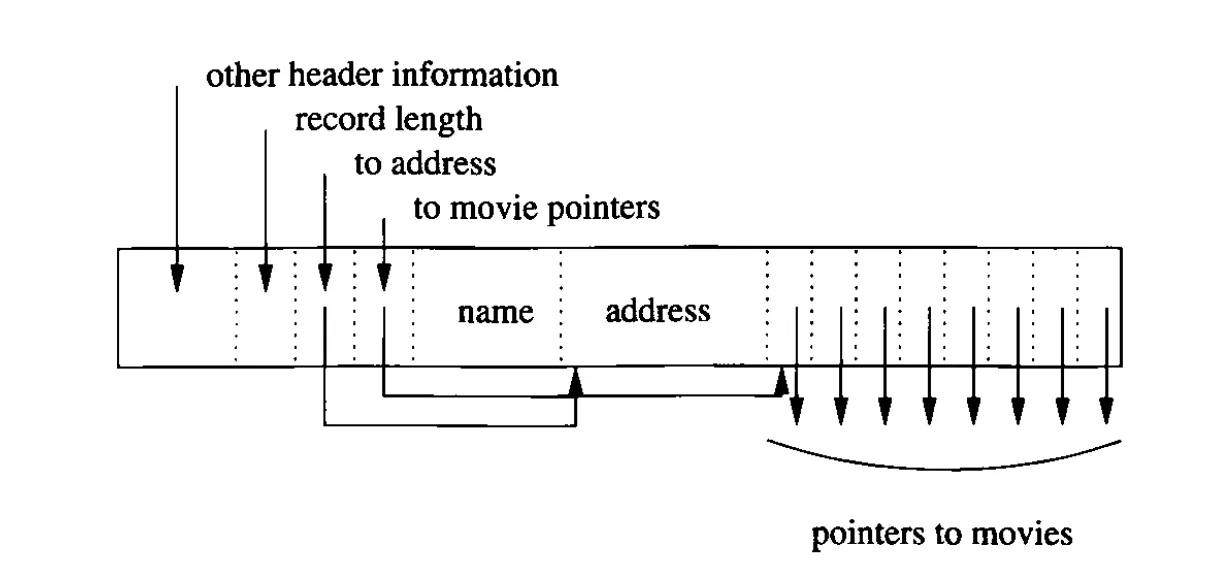
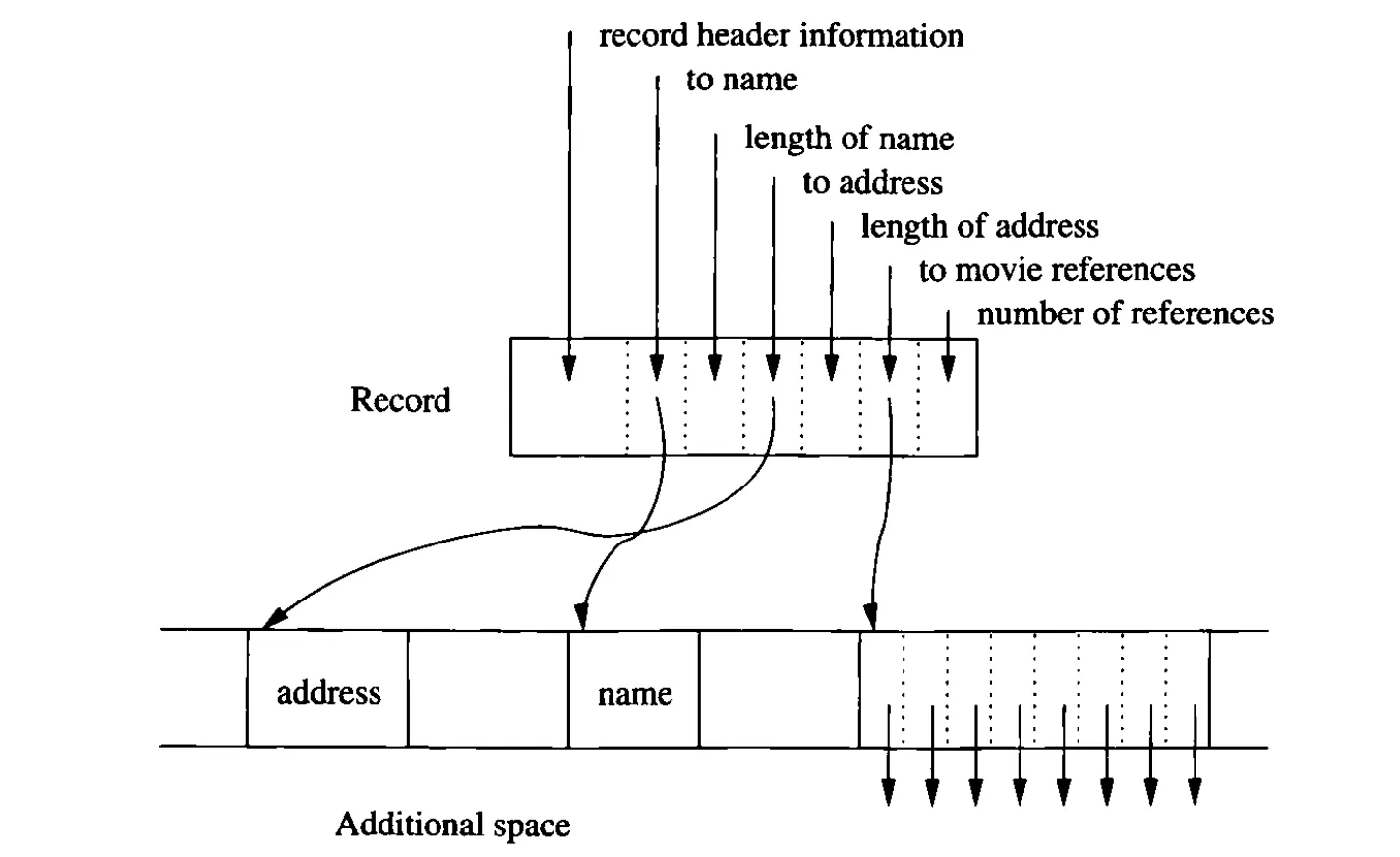
이런 식으로 아예 다른 곳에 저장하는 것도 가능
이러면 장점 → more compact, 단점 → more I/O
3.
Variable format records
a.
JSON 같은 것들
b.
Use tagged fields를 만들어서 self describing이 가능하도록 한다.
Records do not fit in a block
spanned : two or more fragments로 되어있는 record는 spanned이다.
unspanned: block boundary를 넘지 않는 건 unspanned 이다.
각 레코드 헤더는 fragment 되었는지, 첫 번째인지 마지막 fragment인지, 그 다음 fragment인지를 가리킨다.
BLOB
너무 크기 때문에 handle을 잘해야한다.
Storage
•
실린더 상에 연속적으로 나둬야한다.
•
block의 링크드 리스트 형태로 저장 가능
•
여러 disk에 걸쳐서 저장을 해야, 동시에 읽어들일 수 있다.
Retrieval
•
일정한 속도로 retrieve 해서 줌
•
또는 특정 Portion에 대해서 index를 만들어 줄 수 있다. click and jump 같은 기능을 지원하기 위함.
Column store
•
레코드로 저장하는 대신에 column으로 저장할 수 있음.
•
장점
◦
같은 컬럼에 대해서 compress value를 하기가 편하다 → 같은 column은 같은 데이터 타입. 압축할 방법이 많아요.
◦
컬럼에 대해서 많은 양을 쿼링하기가 편하다. → aggregation이 쉽다.
•
row store의 장점
◦
레코드에 대해 읽고 쓰기가 빠르다.
Insertion
•
만약에 레코드가 정렬이 안 되도 된다면, 그냥 빈 공간이 있는 block을 찾아서 넣거냐 new block을 넣으면 된다.
•
ordering이 되야한다면, 약간 복잡해지는데, 일단 적절한 block을 골라야한다.
•
만약에 거기에 자리가 있으면 다행이지만, 없다면 record를 하나씩 다 밀어야한다.
•
만약 그렇다면 block 구성이 offset table을 놓는 형식으로 되는게 유용하다.
◦
block 안에 있는 건 그대로 가리키면 되고, (offset table) 밖에 있는 것들은 해당 블럭과 해당 블럭에서의 위치를 offset table에 넣으면 된다. (structured address)
•
만약에 block에 더이상 자리가 없으면 어떡하냐?
◦
nearby
▪
바로 옆에 있는 block에 대해서 공간이 남으면 순차적으로 밀어버리고, 거기를 forwarding address로 업데이트해서 자리를 만들면 됨.
◦
overflow block
▪
block header에 확장을 할 overflow block을 적어놓고 거기서 확장하면 됨.
Deletion
•
record를 하나씩 밀던가
•
available-space list에 다시 넣어서 유지하던가.
dalgling pointers
•
tombstone을 세우면 됨
◦
offset Table에 null pointer를 박던가
◦
logical→ physical address map에 박던가
◦
레코드 시작전에 특별하게 표시하던가