.jpg&blockId=1b87074d-017e-8069-9667-d5678d39e51d)
Situation
저희 OTL은 원래 AWS 환경에서 운영되고 있었습니다. AWS에서 운영될 때는 너무나도 당연히 모니터링 툴들이 존재했지만, 모든 서버를 물리 서버로 내리면서 문제가 발생했습니다.
문제가 발생해도 알 수가 없다는 것입니다.
uptime kuma를 이용한 health-check 정도만 하고 있었기에 이번 기회에 제대로된 모니터링 시스템을 구축해야겠다고 생각했습니다.
특히 이 작업이 필요해진 결정적인 계기가 있었는데요. 바로 OTL OOM 이슈입니다.
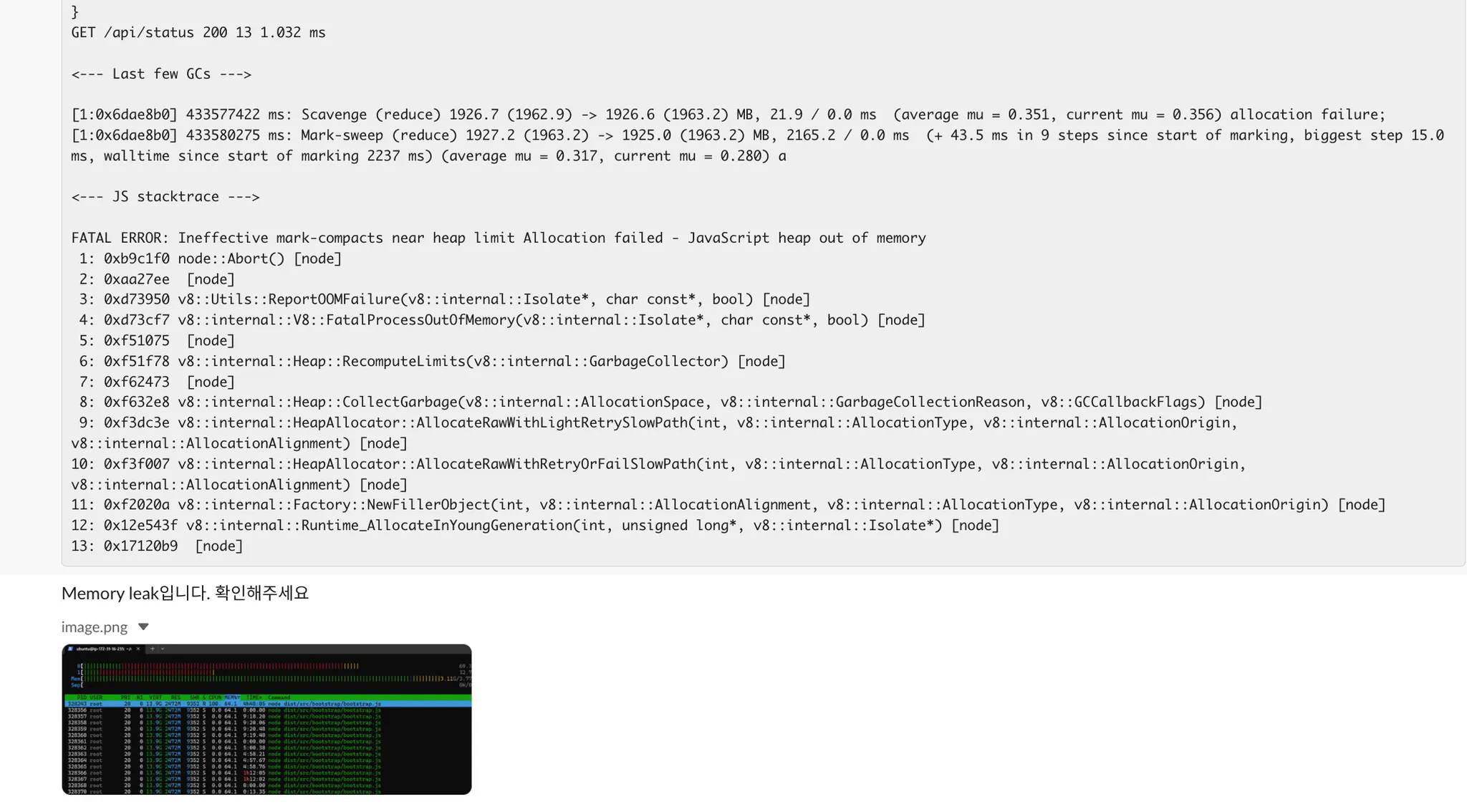
당시 쓰레드에서부터 시작해서 Memory Leak이라고 언급되어서, 저는 Memory Leak을 찾는 다양한 테스트를 진행하였습니다. 아래 링크를 참고하였습니다.

아래는 chrome:inspect로 조사한 결과입니다. 이후 슬랙 메시지와 같이 조치를 취하여 오른쪽 사진처럼 줄였습니다.
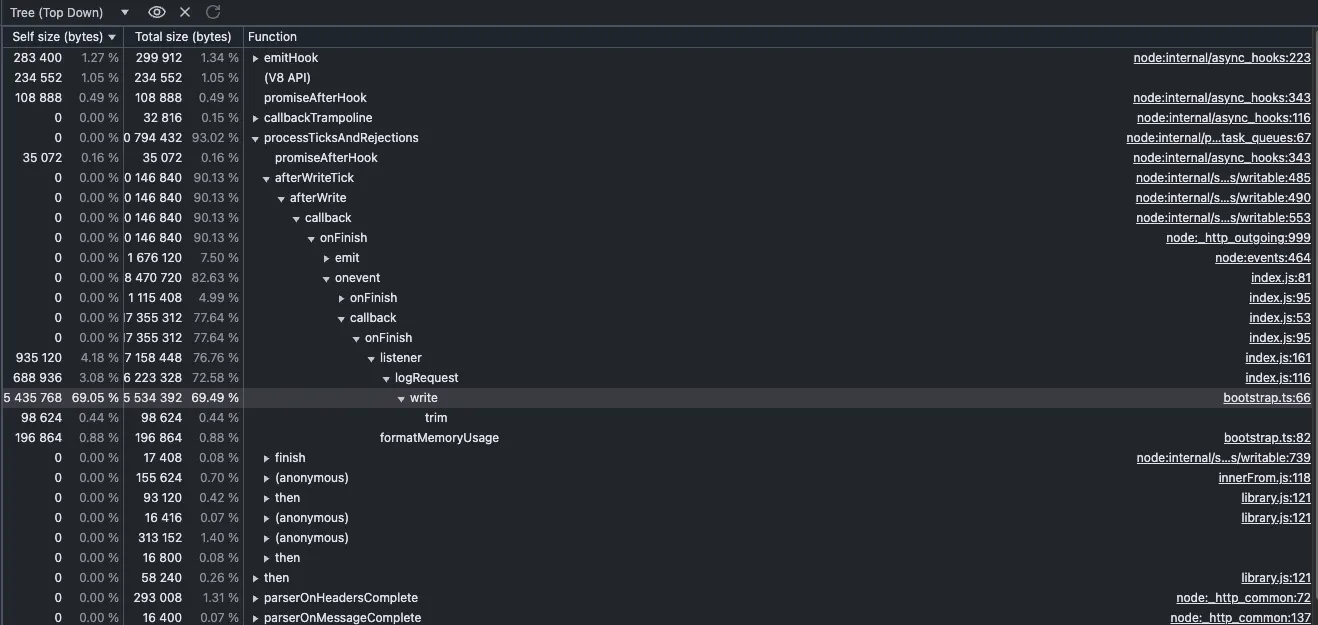
Clinic이라는 라이브러리로도 조사를 해보았습니다.
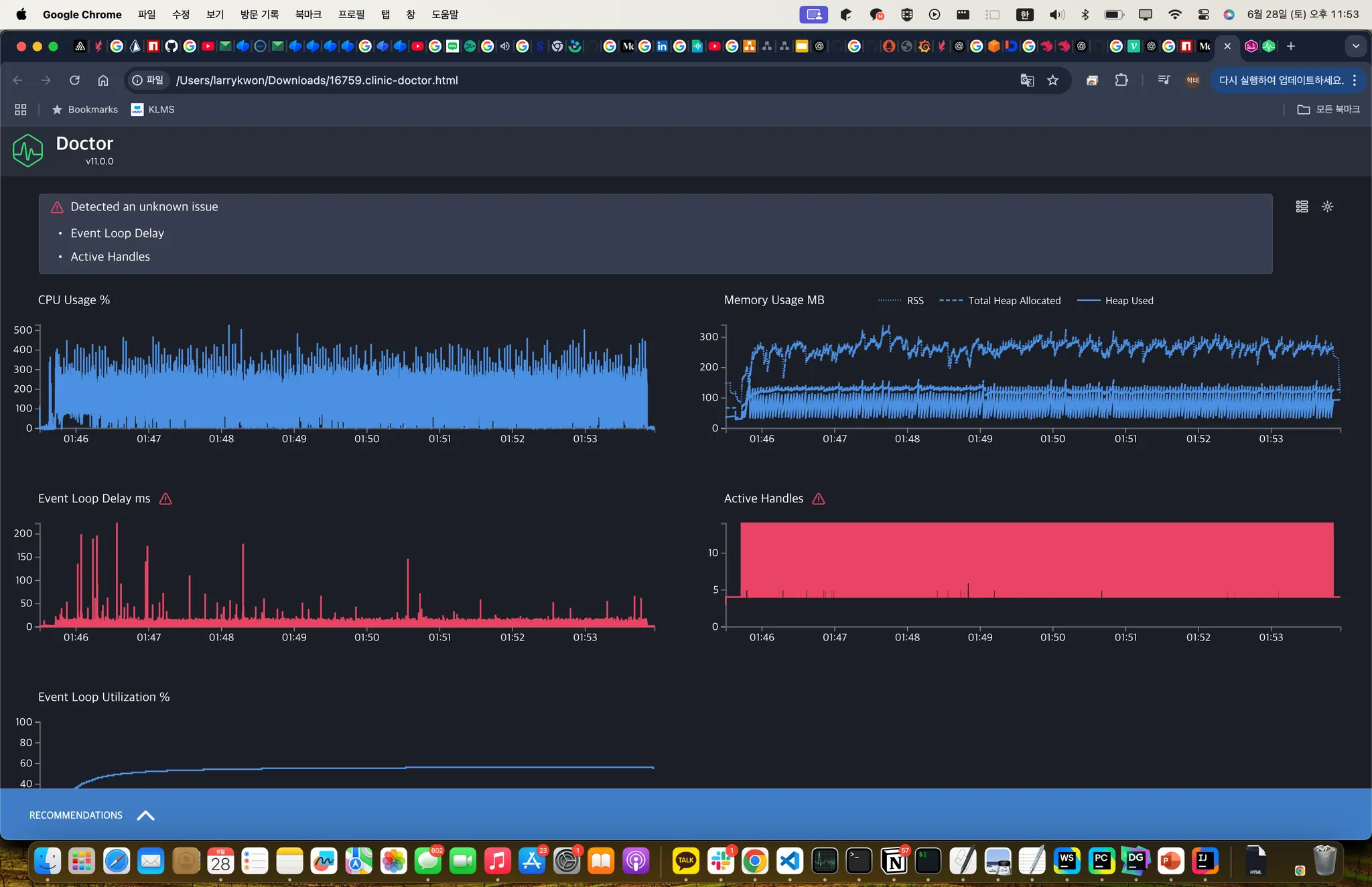

메모리가 늘었다 줄었다 하는 경향을 보이지만, 그래도 전체적으로는 괜찮은 총량을 보여주는데요. 도저히 이유를 알 수가 없었고, 장기적인 관점에서 정말 메모리가 leak이 일어나는 것인지 조사해볼 필요가 있다고 생각하였습니다.
우선은 저 문제로 수동으로 매번 재시작을 해줘야했기 때문에 pm2에서 지원하는 memory restart 옵션으로 일시적으로 크래시를 완화하였습니다.

Task
•
모니터링 시스템을 구축하자
현재 sparcs는 proxmox를 기반으로 해서 여러 VM을 손쉽게 관리하고 있습니다. 쿠버네티스 기반은 아니지만 격리성이 좋은 VM으로 전체 서비스를 유지하고 있습니다.
추후 쿠버네티스로 이전하는 것을 고려하여 prometheus + grafana로 이번 모니터링 툴을 세팅하기로 하였습니다. 프로메테우스에 관한 공부는 아래 블로그를 참고하였습니다.


이 구조를 학습하면서 신기했던 것은 pull 구조인데요. 쿠버네티스를 기반으로 확장성이 가능하게 설계하다보니 pull 구조로 설계를 한 것이 아닐까 싶습니다.
뿐만 아니라 기존의 push에 비해서 관측의 주도성을 프로메테우스가 담당한다고도 볼 수 있습니다. 기존에 push 구조에서는 메트릭이 오지 않으면 왜 오지 않는지 prometheus가 모르지만, pull 구조이기 때문에 접속 오류인지, 타임아웃인지, 500 상태인지 등을 바로 알 수 있는 것도 장점인 것 같습니다.
덕분에 저도 세팅하는데 있어서 왜 프로메테우스 exporter에서 메트릭을 못 가져오는지를 바로바로 알 수 있었기에 도움이 되었고, 조금은 수월하게 세팅을 할 수 있었습니다.
또한 우려했던 것은 prometheus의 확장성인데요.
공식 문서에 아무리 보아도 원격 저장소에 저장할 수 있는 방법이 존재하지 않았습니다. 무조건 하드 디스크에다가 저장하는 것으로 되어있는데요. 이 부분은 서치를 통해 mimir 라는 원격 저장소가 따로 있는 것을 확인했습니다.
현재는 하드 디스크에 저장하는 식이며 저장공간이 부족해지는 경우 mimir로 세팅을 확장하고자 합니다.
Action
작업물은 아래 레포에서 확인할 수 있습니다.
모든 exporter는 도커로 동작합니다. 또한 관리가 필요한 VM들 별로 디렉토리를 별도로 두어 exporter를 관리하고 모니터링 서버에는 prometheus.yml을 정의합니다.
현재 운영 중인 exporter는 다음과 같습니다
•
node-exporter: 호스트 머신 모니터링
•
cadvisor: 컨테이너 모니터링
•
nginx-exporter: nginx 모니터링, but nginx-vhost와 비교해서 너무 간단한 것들만 있어 추후 보강 예정
•
Redis-exporter: Redis 캐시 히트율 및 메모리 사용량 모니터링
•
swagger-stats:  Interface 기반 Swagger Document 생성기 개발 에서 swagger 문서를 생성함으로써 swagger-stats라는 라이브러리를 이용하여 prometheus로 APM이 가능해졌습니다. 표준적이지는 않는 방법이지만 임시로 사용하는 중입니다.
Interface 기반 Swagger Document 생성기 개발 에서 swagger 문서를 생성함으로써 swagger-stats라는 라이브러리를 이용하여 prometheus로 APM이 가능해졌습니다. 표준적이지는 않는 방법이지만 임시로 사용하는 중입니다.
Interface 기반 Swagger Document 생성기 개발 에서 swagger 문서를 생성함으로써 swagger-stats라는 라이브러리를 이용하여 prometheus로 APM이 가능해졌습니다. 표준적이지는 않는 방법이지만 임시로 사용하는 중입니다.◦
추후 적절한 APM 툴을 조사하여 세팅할 예정입니다. opentelemetry를 고려 중입니다
◦
현재는 sentry-tracing을 켜서 성능 최적화 진행 중입니다.
이와 별개로 sentry의 self-hosted가 가능함을 알게 되었습니다. 에러 리포트 기능이 절실했는데 이 기회에 셋업을 진행하였습니다.
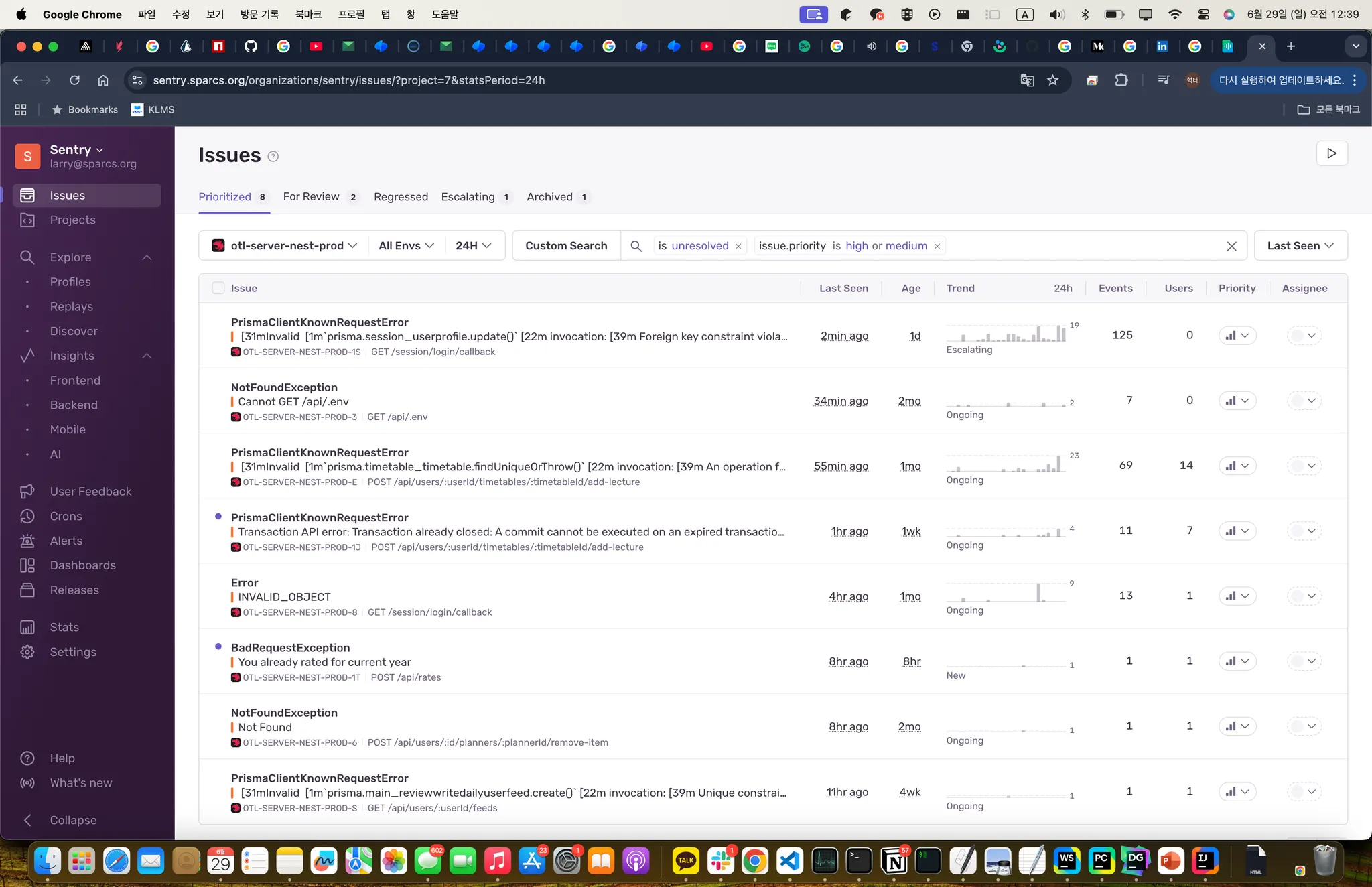
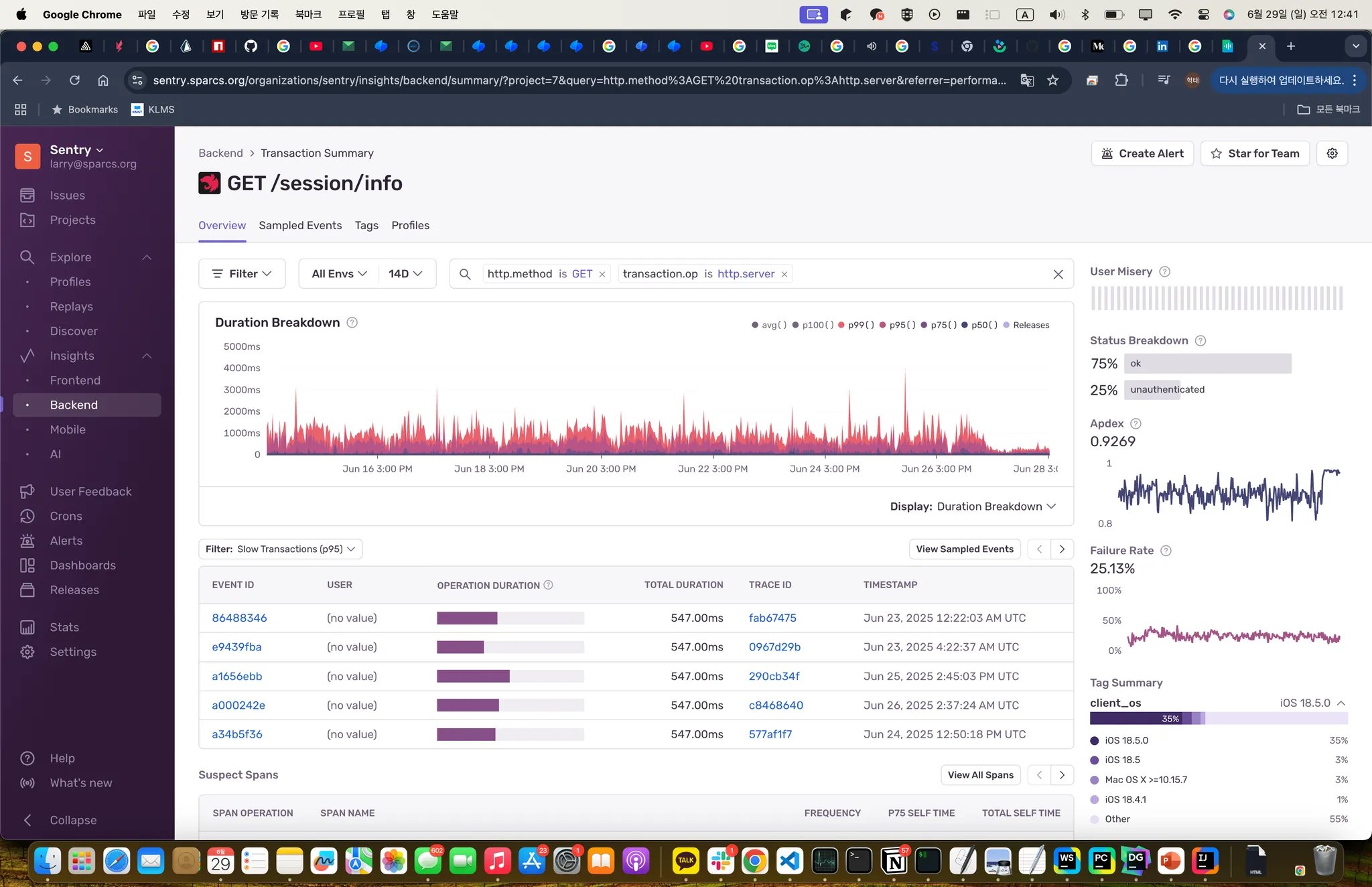
Result
Swagger Stats


Node-exporter


Cadvisor
아직 다음과 같은 할 일이 많이 남았습니다.
•
grafana alerts 설정
•
grafana 계정을 구글 oAuth로 연결
•
metric 수집 VPN 세팅
•
장기 저장을 위한 mimir 도입
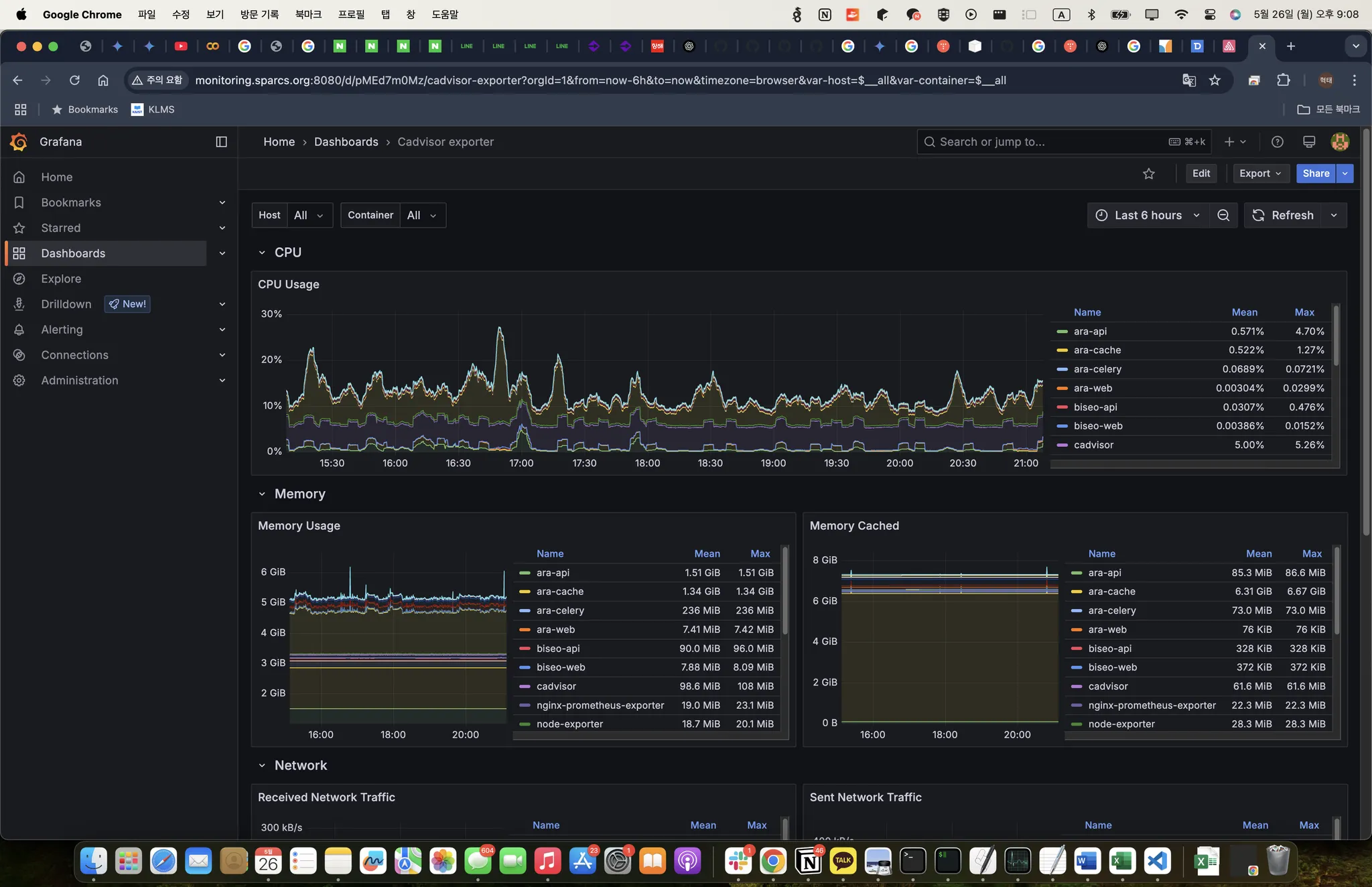
그래서 위의 메모리 문제는 어떻게 되었을까요? 아직 원인을 찾지 못했습니다. 다만 확실한 것은 memory leak은 아니란 것입니다.
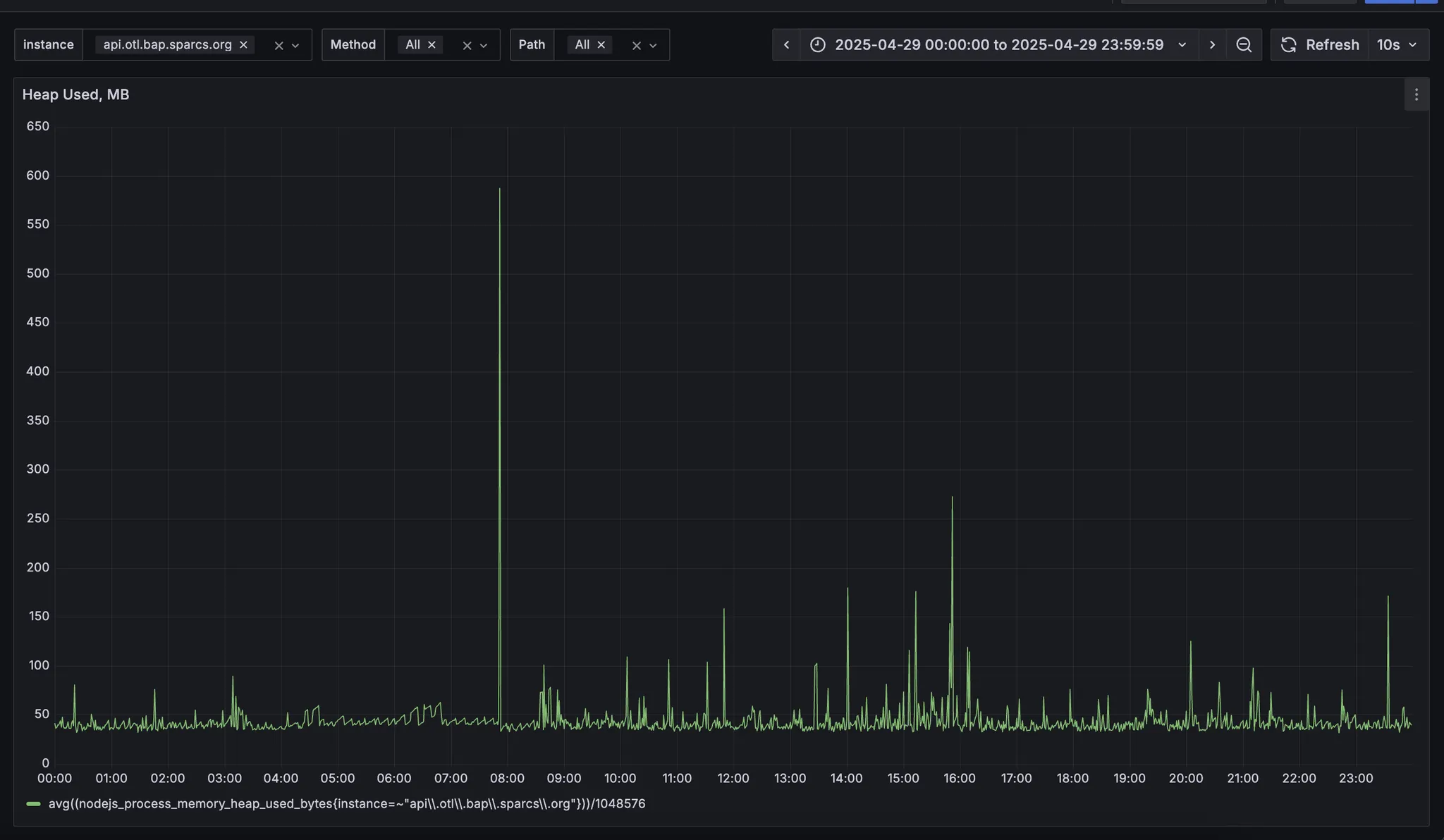
주요 논점은 동작하는 호스트 머신에 따라 메모리 사용량 그래프가 완전히 다르게 나타난다는 것입니다. 또한 node 메모리를 추적했을 때는 두 머신에서 동작하는 NestApplication은 매우 안정적으로 유지됨을 알 수 있었습니다.

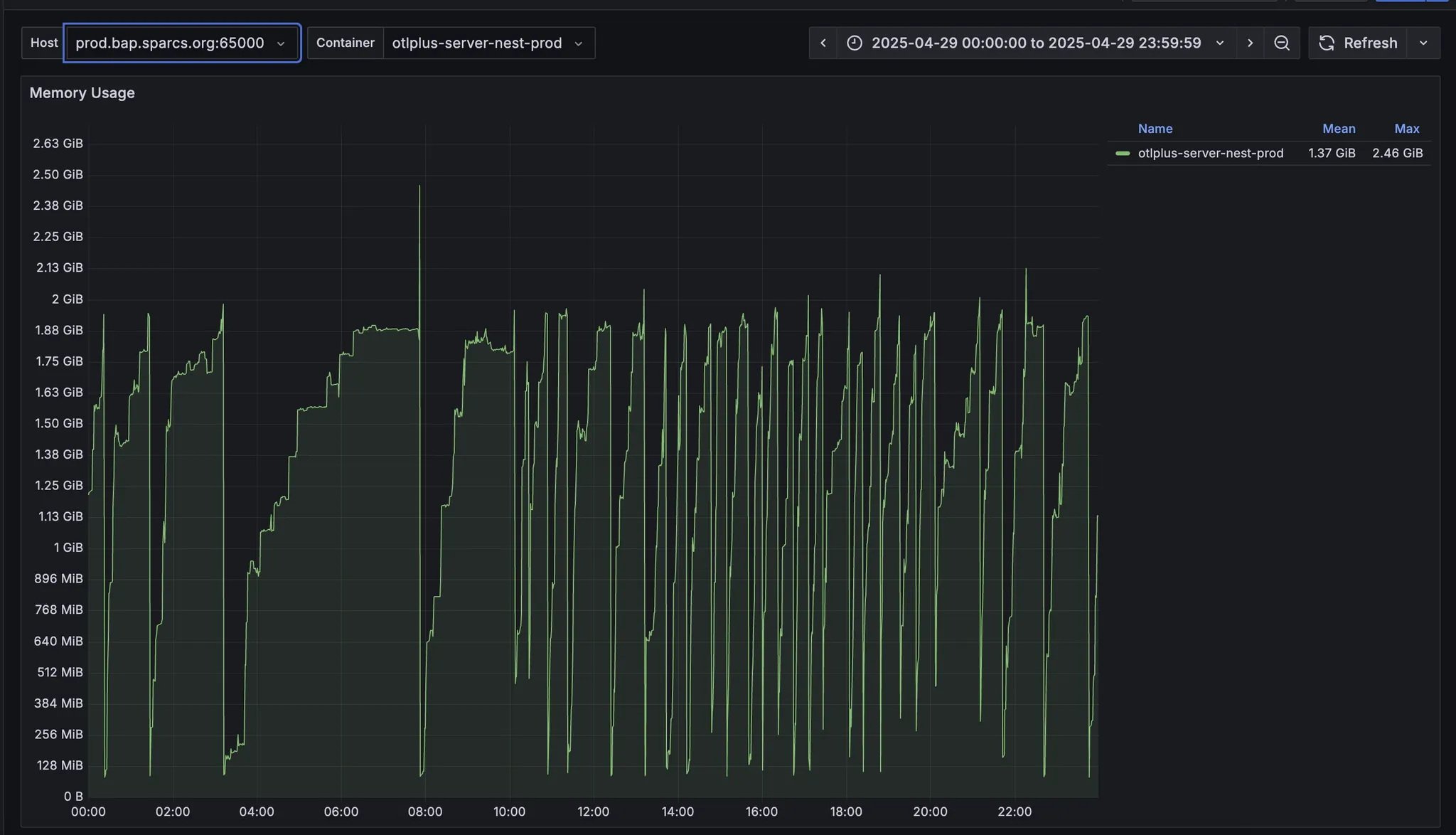
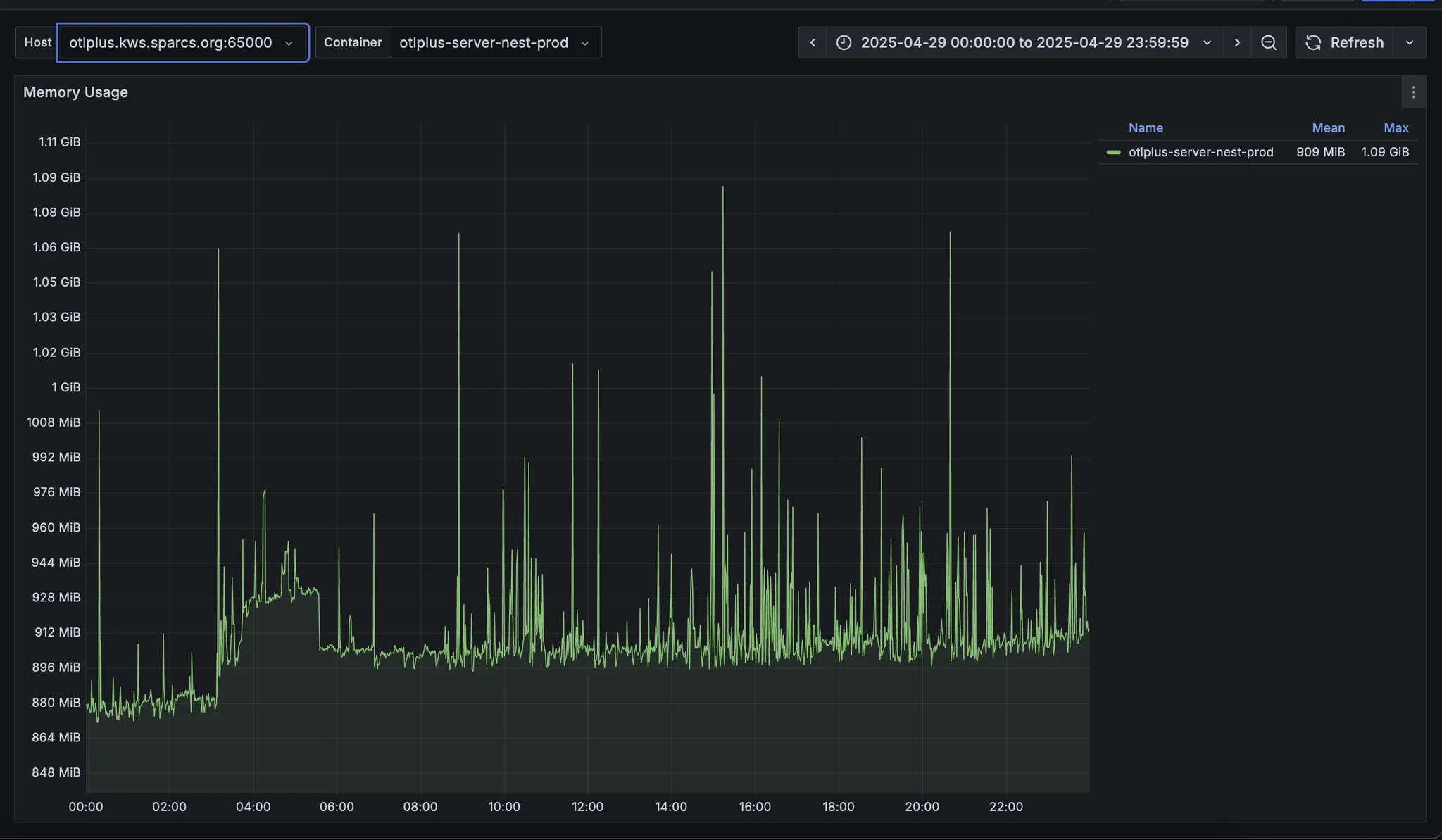
반면 cadvisor로 측정되는 메모리는 얘기가 달랐는데요. 머신에 따라 메모리 사용량 그래프가 다르게 나타났습니다.
Reflection
이번 에피소드에서는 prometheus를 기반으로한 셋업과 그 결과를 공유해보았습니다.
observability를 확보함으로써 많은 부분에서 개선이 이루어졌는데요. API의 경우에는 계속해서 개선이 이루어지고 있습니다.
grafana의 경우에는 앞으로 grafana alerts를 통해 즉각적인 알림을 받는다면 좀 더 활용도가 높아질 것 입니다.
현재 MySQL exporter가 사용자 인증 문제로 동작하고 있지 않는데, 2025 가을 수강 신청 이전에 빠르게 작업하여 수강신청 장애 대응에 좀 더 도움이 되고자 합니다.