.jpg&blockId=1b87074d-017e-8069-9667-d5678d39e51d)

Situation
오믈렛 회사에서 맨 처음 맡았던 Task 입니다. 경로 최적화 문제를 푸는 모델이 있었는데 이를 파이썬 패키지로 만든 후 Django에 임포트하여 사용하고 있었습니다. 주요 문제 상황은 해당 도커 이미지가 너무 크다는 것이었습니다. 이에 Elastic Beanstalk으로 배포를 하고 싶었으나 ECR에서 다운받을 때 이미지가 너무 커서 다운로드 받는데서 타임아웃 문제가 발생했습니다.
Task
최초 빌드는 압축 시 9기가 정도였고, 이 크기를 줄이는 것이 태스크였습니다. 도커 이미지를 줄이는 방법을 검색하면서 멀티 스테이지 빌드를 공부하게 되었습니다.
그 전에 도커 이미지 빌드에서 ‘레이어’라는 개념을 접하게 되었습니다.
FROM ubuntu:20.04 # 레이어 1
RUN apt-get update # 레이어 2
RUN apt-get install -y python3 # 레이어 3
COPY . /app # 레이어 4
Docker
복사
아래 처럼 명령어 한줄에 하나의 레이어를 이루게 됩니다. 한 번 만들어진 레이어는 변경되지 않으며, 읽기 전용으로 우선 시작했다가 컨테이너만 쓰기 가능한 임시 레이어를 위에 올려서 쓰기 작업은 그 공간에서 쓰게 됩니다. 뿐만 아니라 한 번 이미지에 복사한 파일은 이미지에서 뺄 수 없습니다.
이런 개념을 학습한 후에 멀티 스테이지를 공부해보니, 멀티 스테이지는 실행환경과 빌드 환경을 분리하는 것이 목적이었습니다. 여러 스테이지를 구성하고 이전 스테이지에서 만든 걸 들고오는 식으로 최종 이미지에는 필요한 파일만 담기게끔 하는 식입니다. 이를 이용하면 이번 Task에서도 추론에만 필요한 torch만 남기는 식으로 해결할 수 있을 것이라 생각하였습니다.
이 때 GPU 추론을 도커에서 실행시키려면 특별한 도커 이미지에서 실행해야합니다.
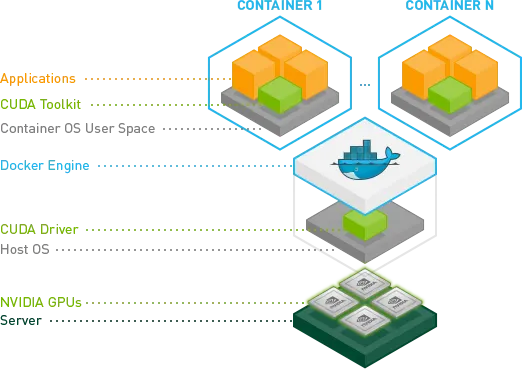
이유는 위처럼 CUDA Driver가 깔려있어야하기 때문인데요. 아무래도 Driver라는게 OS 단에서 설치되는 것이기 때문에, 그 위에서 독립적인 환경으로 관리되는 Container는 직접 호스트 머신과 통신할 수 있어야하기 때문일 것입니다. 이를 연결해주는 요소가 바로 nvidia-container-toolkit 입니다. 이는 호스트 머신의 nvidia GPU를 컨테이너가 접근할 수 있게 해줌으로써 nvidia-smi 명령어를 쳤을 때, 호스트 머신의 드라이버가 드러나도록 하는 역할입니다.
하지만 공부를 할 수록 GPU inference가 필요한 경우에만 의미가 있음을 깨달았고, 꼭 GPU를 써야하냐고 물어보았습니다. 이 과정에서 지금 당장은 필요 없다고 하셔서 CPU 버전을 따로 제작하여 배포를 할 수 있었습니다.
따라서 최종적으로는 2개의 파일을 만들게 되었는데, GPU 버전과 CPU 버전을 만들었습니다. GPU 버전의 경우 압축시 3기가, 압축 해제 시 한 5-6기가가 되는 빌드이미지였고, CPU 버전의 경우 몇 백 메가 단위로 줄어들었습니다.
Reflection
•
GPU 버전 도커 이미지 제작
◦
우선 GPU 버전의 도커 이미지를 제작하긴 하였으나, 이것이 정상적으로 실행되는지 확인해보지 못한 아쉬움이 남습니다.
•
ML 모델 서빙
◦
GPU 추론을 써야하는 때가 온다면, Django에 패키지화해서 넣는 것이 아니라, 비동기 처리를 지원하는 FastAPI 를 사용하거나 torchserver나 betoML 같이 ML 모델을 서빙하는 프레임워크를 사용하면 좋을 것 같습니다
◦
Triton
▪
대규모 GPU 서버에서 다양한 프레임워크 모델을 동시에 서비스
▪
TensorRT 최적화 + batching + gRPC 필요할 때
▪
Kubernetes와 연동 시 강력
◦
TorchServe
▪
학습된 PyTorch 모델을 REST/gRPC API로 빠르게 배포하고 싶을 때
▪
기본적인 서빙만 필요한 내부 서비스
◦
FastAPI
▪
전처리/후처리가 복잡한 로직이 섞인 API 서비스에 적합
▪
추론 외에도 다양한 엔드포인트 (/predict, /health, /upload)가 필요한 경우
▪
MLOps보다는 API 개발 중심
◦
BentoML
▪
End-to-End MLOps (모델 저장 + 서빙 + 배포)까지 포함된 플랫폼을 원할 때
▪
다양한 프레임워크를 섞어 서빙할 수 있어 팀 협업에 좋음
▪
자동 Dockerization, REST API, Lambda 배포까지 모두 포함
•
의사 소통 관련
◦
처음부터 GPU 버전이 필요 없다는 것을 충분한 의사소통을 통해 알게 되었다면, 더 빠르게 일을 처리할 수 있었을 것 같습니다. 다만, 이 기회를 통해 MLOps landscape를 알게 되었습니다.
•
Multi-stage build
◦
이 경험을 통해서 Docker Layer의 이해, 멀티 스테이지 빌드 스크립트 작성법을 익히게 되었습니다.
◦
이 경험을 통해 OTL 서버 이미지 또한 줄일 수 있었습니다.