.jpg&blockId=1b87074d-017e-8069-9667-d5678d39e51d)
Summary
긴 에피소드이기에 요약을 적어놓았습니다
Situation
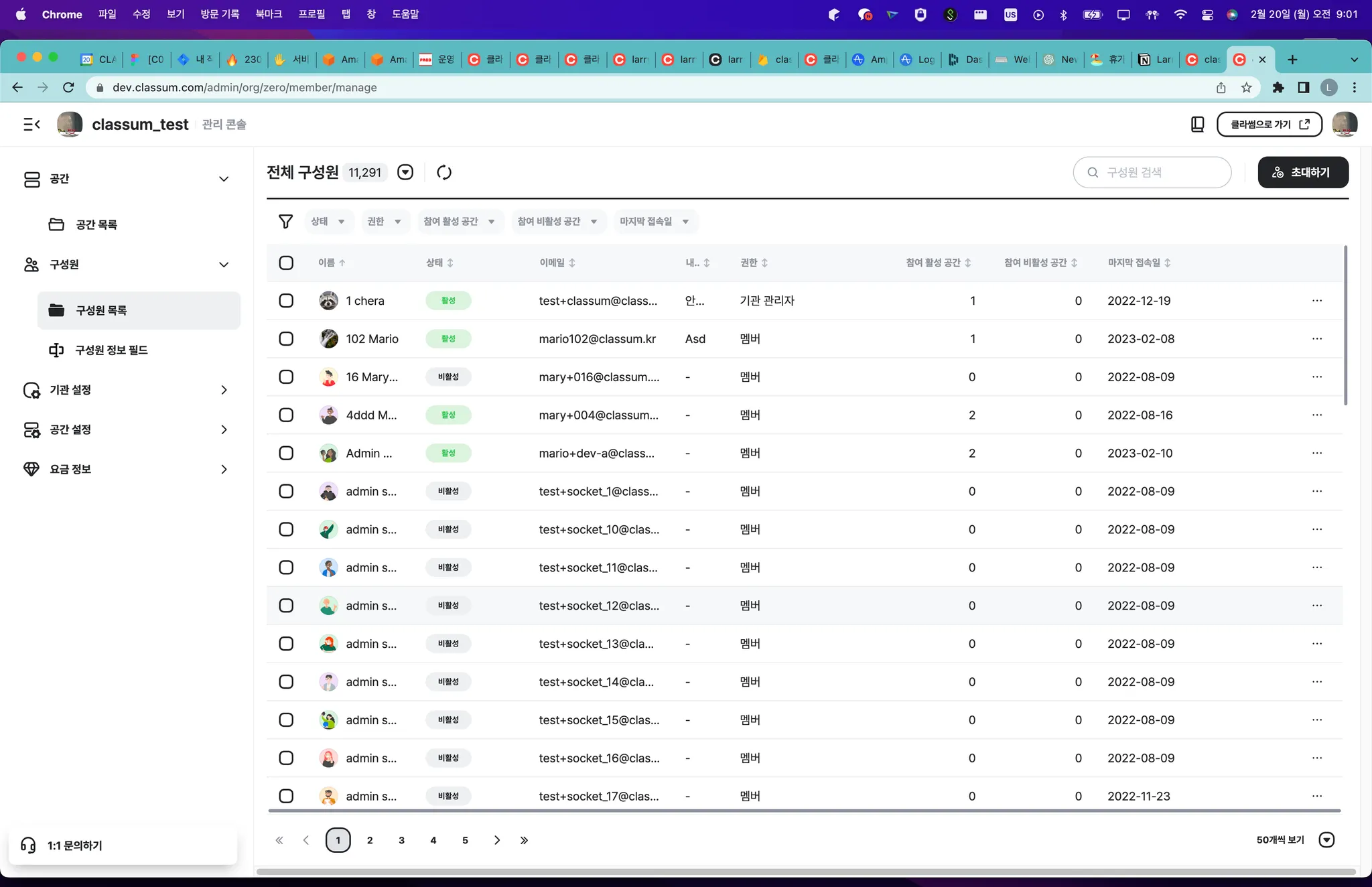
현재 서비스 중인 관리 콘솔의 구성원 목록 페이지입니다.
백엔드 입장에서 구현해야하는 기능을 살펴보자면 다음과 같습니다.
표시해야하는 항목
•
이름 (displayName, instituteMember)
•
status(없음)
•
이메일(user)
•
내 소개 (message, instituteMember)
•
권한 (roleType, instituteMember)
•
참여 활성 공간 (없음)
•
참여 비활성 공간 (없음)
•
마지막 접속일 (courseToUser, instituteMember)
•
각종 커스텀 필드 목록들
지원 기능
•
상태,권한,참여 활성 공간, 참여 비활성 공간, 마지막 접속일에 대한 필터링
•
이름, 상태, 이메일, 내 소개, 권한, 참여 활성 공간, 참여 비활성 공간, 마지막 접속일에 대한 정렬
•
전체 검색
•
테이블 페이지네이션 (전체 구성원 수 + 현재 페이지 앞 뒤로)
•
거의 실시간으로(새로고침 시) 활성 공간 수 또는 비활성 공간 수가 바뀌어야 함.
•
커스텀 필드 값에 대한 업데이트 및 관리자의 커스텀 필드 업데이트에 대한 변화가 즉시 반영되야함.
Problems
다음과 같은 문제를 해결해야했습니다.
1.
구성원 목록 페이지를 불러오는데 2초 정도 걸린다.
2.
커스텀 필드로 인해 성능이 또 저하된다.
Task
구성원 목록 페이지 Read Issue
•
쿼리 최적화를 통해 쿼리 성능을 높여야합니다.
Custom Profile Issue
•
마찬가지
Action
구성원 목록 페이지 Issue
초기 쿼리는 다음과 같았습니다.
초기 쿼리
초기 쿼리의 특징이라면 다양한 데이터를 filtering, ordering이 가능하도록 들고오는 것입니다.
특히 참여 공간에 대한 통계 때문에 모든 데이터를 한 번 더 들고와야합니다.
뿐만 아니라 courseToUser와 instituteMember의 조인으로 인한 쿼리 비용 상승하고 있습니다.
courseToUser는 사용자와 조직 내 공간에 대한 매핑, instituteMember는 사용자와 조직에 대한 매핑입니다.
개선은 총 2가지 단계로 이뤄졌습니다.
1.
쿼리 개선
2.
테이블 구조 개선
쿼리 개선의 경우 불필요하게 전체 카운트를 위해 1번, 전체 목록을 위해 한 번 이렇게 두 번씩 호출하는 부분이 있어 해당 부분을 없앰으로써 시간을 줄였습니다. 마지막 접속 일자를 서브 쿼리로 뺌으로써 시간을 단축시켰습니다.
위의 방법으로도 시간이 줄어들지 않아서 대책을 강구하면서, 통계 테이블처럼 테이블 구조를 바꾸기로 하였습니다.
테이블의 이름은 __mv_institute_member_statistics 이고, 해당 테이블에는 활성 공간 수, 비활성 공간 수, 마지막 접속일 등을 저장하고 있습니다. 따라서 쿼리는 아래처럼 간단해졌습니다.
통계 테이블 생성 후 쿼리
그렇다면 __mv_institute_member_statistics 테이블에 어떻게 데이터를 넣는지 얘기를 해야할 것 같습니다.
총 세 가지 방법이 있는데,
1.
스케줄러로 정기적으로 맞추는 방법
2.
특정 액션이 일어날 때마다 다시 세는 방법
3.
특정 액션이 미치는 영향을 파악해서 increment, decrement를 하는 방법
개발의 난이도와 일정상 2번을 시도해보고 1,3번을 시도했습니다.
이 과정에서도 count는 너무 느려서 포기했고, Entity Model에 대한 CRUD가 일어날 때, 이를 구독하는 Subscriber를 TypeORM이 지원하는 것을 확인하여 이를 활용하고자 하였습니다. 하지만 이 방법 또한 특정 액션에 대해서는 이벤트가 잡히지 않는 이슈가 있었는데 TypeORM 특정 버전 이하에서 일어나는 이슈였습니다. 그렇다고 버전을 올릴 수가 없었던게 TypeORM이 0.3버전으로 올라가면서 datasource라는 형식을 사용하는 식으로 크게 변경되었기 때문입니다. 저희는 0.3 이하 버전을 사용하고 있었고, 해당 이슈는 0.3 버전 이상부터 해결되었습니다.
따라서 관련한 API 엔드포인트에서 increment, decrement를 해주는 식으로 구현하였으며, 통계 오류를 잡아줄 scheduler를 구현하였습니다. 커스텀 프로필이 없는 상태에서는 큰 폭으로 성능이 좋아져, 600ms 밑으로 API 응답이 유지되었습니다.
Custom Profile Issue
이전에 소개 드렸던 데이터 구조에서는 다음과 같은 상황에서 성능 문제가 발생합니다.
1.
조회
2.
수정 & 삭제
조회
먼저 조회부터 보게 되면, 구성원 목록을 불러오는 곳에서는 현재 페이지가 몇 페이지인지랑 상관없이 항상 기관 구성원 * 커스텀 필드 수만큼의 데이터를 불러와야합니다.
이유는 정렬 기능 때문인데, 정렬 기능을 db 단에서 이용하려면 db에서 select하는 가상 테이블의 크기가 전체 목록의 수와 딱 맞아야합니다. 그렇게 되면 특정 컬럼으로 정렬 했을 때, 1페이지라면 첫 번째 50개만 잘라서 들고오고 이렇게 할 수 있는데 현재는 다중선택 타입의 커스텀필드로 인해 중복 row가 생겨서 그런 식으로 정렬을 할 수 없습니다.
문제는 구성원이 만 명인 기관에서 5개의 선택지가 있는 5개의 필드를 모두 쿼리하기로 했을 때, 25만개가 한 꺼번에 들고와진다는 것입니다. 이 수는 거의 기능 requirements의 minimum한 숫자라서 계속 증가할 예정이었습니다.
하지만 저희 DB는 25만개 row를 select하는 경우에 굉장히 느립니다. 이유는 DB의 IO 때문입니다. 25만개의 row 전체를 들고오려면 메모리 상에서 들고오기는 힘들고 디스크까지 접근을 해야하는데, 이 때 굉장히 느려집니다. 여러 번 테스트를 해본 결과 10만개 정도가 한계인 거 같습니다. 간단한 해결책 중 하나는 db의 메모리 버퍼를 늘리는 것입니다. 현재 db 전체 메모리의 75프로로 설정되어있는데, aws의 구조상 50프로만 사용합니다.
해당 내용을 링크로 참조해놓겠습니다.


또 다른 방법은 행으로 되어있는 것을 열로 바꾸는 방법입니다. 하지만 이는 정말 아닌거 같습니다…
또 다른 방법으로는 누가 어떤 커스텀필드를 가지고 있는지를 문자열로 나타내고 이를 통해 select 해오는 열의 수를 줄이는 것입니다. 이는 뒤에서 얘기해보겠습니다.
삭제
커스텀 필드를 삭제하거나, 필드 옵션을 삭제하는 경우에 대량의 row를 delete를 지워야합니다. 모두가 사용하는 필드가 삭제되는 경우에는, 최소 전체 구성원의 수부터 구성원 수 * 선택지 수 만큼이 삭제 됩니다. 일괄로 저장하는 UI 때문에 더 늘어날 수 있습니다.
해결방법
최종적으로는 현재 어떤 필드를 선택했는지를 문자열로 나타내기로 하였습니다. 간단히 얘기해서 DB schema에서 customFieldToMember가 원래는 한 행이 하나의 (사용자, 커스텀 필드 값)을 나타내는 것이었는데, 약간의 비정규화를 통해 row수를 줄이고, 각 row에는 누가 어떤 값을 가졌는지를 json으로 저장하는 것입니다.
이렇게 하면 탐색해야하는 row와 DB 메모리 사용량도 줄어서 괜찮은 방법으로 보였습니다. 또한 만 명이 있는 기관에서 커스텀 필드가 5개 정도 있는 상황에서, 모든 사람들이 사용하는 필드를 삭제하는 경우에 5만개 row를 한 번에 삭제해야하는데 이는 DB Index를 통해서 최적화한 결과 500ms 안에 가능했습니다.
이 방식으로 구현한 후에 성능을 테스트해보았습니다.
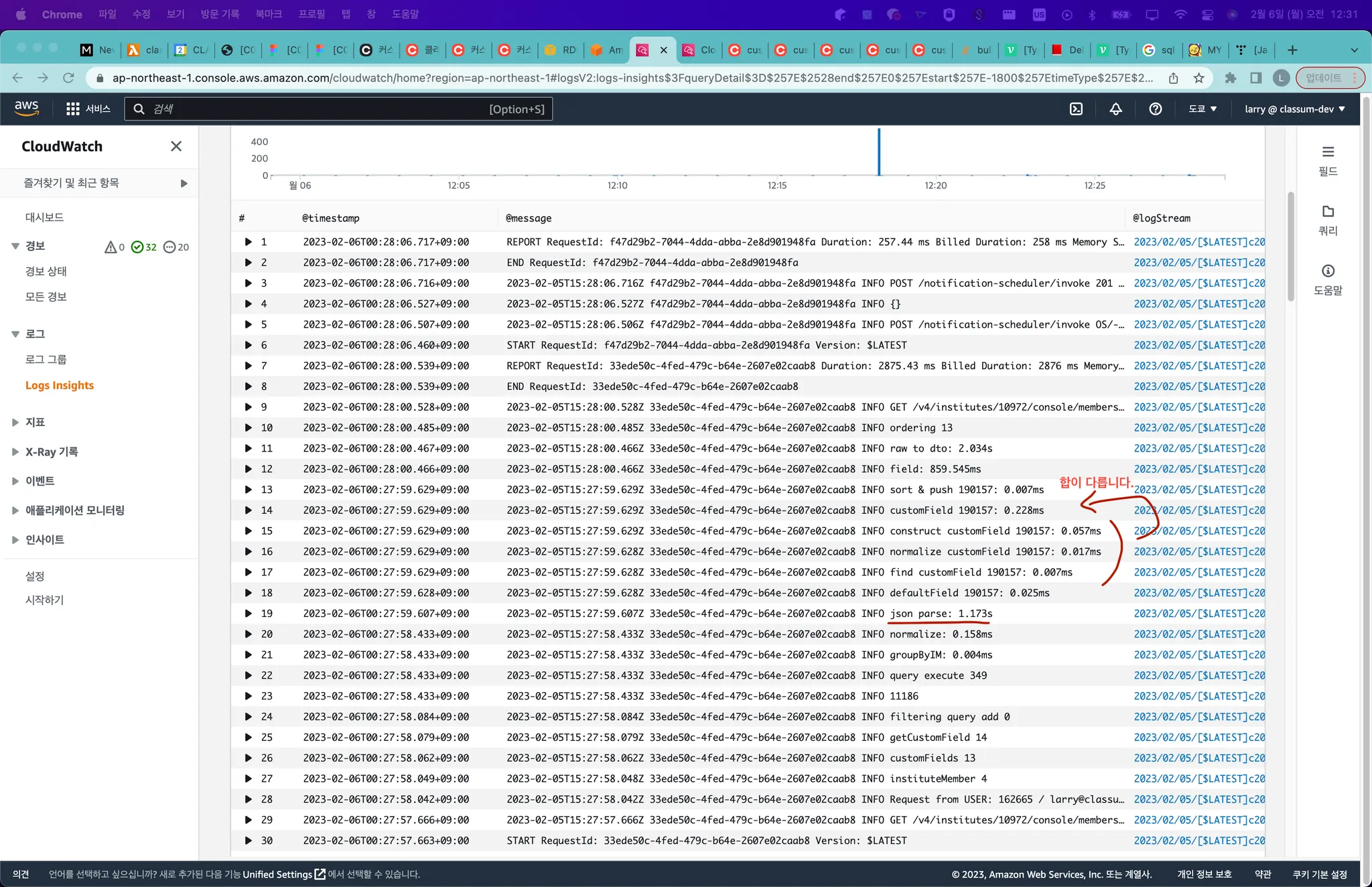
json으로 저장한 후에 들고오는 식으로 구현을 했고, 이 과정에서 추가적인 이슈가 나왔습니다. 특히 json parse 시간과 field에 대한 mapping이 오래 걸렸습니다.
json parse의 경우는 크게 두 가지 방식이 있는데, 들고온 전체 json을 합쳐서 한 번에 json parse를 하는 것이 있고, 각각 들고온 json을 구성원 수 만큼 parse하는 방식이 있습니다. 위 사진은 전자의 경우인데, 후자 방식으로 하면 약간 줄어듭니다.
이를 해결하기 위해 JSON.parse() 나 JSON.stringify() 외의 다른 직렬화/역직렬화 방식을 찾아보았습니다. 이 과정에서 protobuf라는 메시지 압축 기술을 찾게 되었습니다. protobuf는 구글에서 개발한 object를 문자열이 아닌 binary로 직렬화하는 방식입니다. Java에서 Object를 바이너리 코드로 바로 직렬화하는 경우를 본 거 같은데, 주로 live streaming이 필요한 서비스에서 API나 스트림 데이터 응답 처리를 할 때 많이 쓴다고 합니다. (https://protobuf.dev/)

Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
딱 맞는 유즈케이스는 아니지만, 저희도 직렬화/역직렬화의 속도 최적화를 해야하니 사용해보기로 하였습니다.
그리고 실제로 protobuf를 사용했을 때 한 30프로 정도 줄어듭니다. 그러면 최대 600ms 까지 줄일 수 있을 것 같습니다. msgpack이란 비슷한 라이브러리 또한 테스트해보았으나 성능이 그렇게 좋지 않았습니다.
해당 방식으로 DB 구조를 바꾸면서 쿼리도 다음처럼 바뀌게 되었습니다.
수정 쿼리
이 구문의 핵심은 group_concat 입니다. 여러 row로 받아오는 결과를 하나의 컬럼에 delimiter로 잘라서 보여주는 것입니다.
어차피 우리는 완벽한 정규화가 아닌, 비정규화를 통해 속도를 달성했기에 delimiter만 잘 설정해주면 되었습니다.
이를 통해 앞에서 얘기한 ordering을 DB 단에서 할 수 있었기에 추가적인 최적화가 필요 없을 정도로 속도는 훨씬 빨라졌고, 최종적으로는 600ms 안으로 줄였습니다.
회고
극한의 최적화를 경험할 수 있었습니다.
지금 살펴보니 근본적인 해결책이 달랐던 것 같습니다.
우선 삭제의 경우에는 약 5만 row를 한 번에 삭제하는 케이스가 발생하는데, 이는 Message Queue를 이용하여 천천히 consume 되도록 해야하지 싶습니다.
또한 조회의 경우 커스텀 필드에 해당하는 값은 No-SQL 베이스의 DB를 쓰는게 맞는 것 같습니다. 특히 다음과 같이 빠른 검색이 필요한 경우 ElasticSearch를 사용하는 것이 더 좋은 선택지가 아니었나 하는 생각이 듭니다.
ElasticSearch와 DB 간의 동기화 문제가 있을 수 있지만, 이 또한 Message Queue를 통해 적절히 업데이트해주면 될 것 같습니다.
이와 비슷하게 Custom Field의 경우, institute member와 함께 group_concat을 하는 materialized view를 설정해놓는 것도 방법일 것 같습니다.