.jpg&blockId=1b87074d-017e-8069-9667-d5678d39e51d)



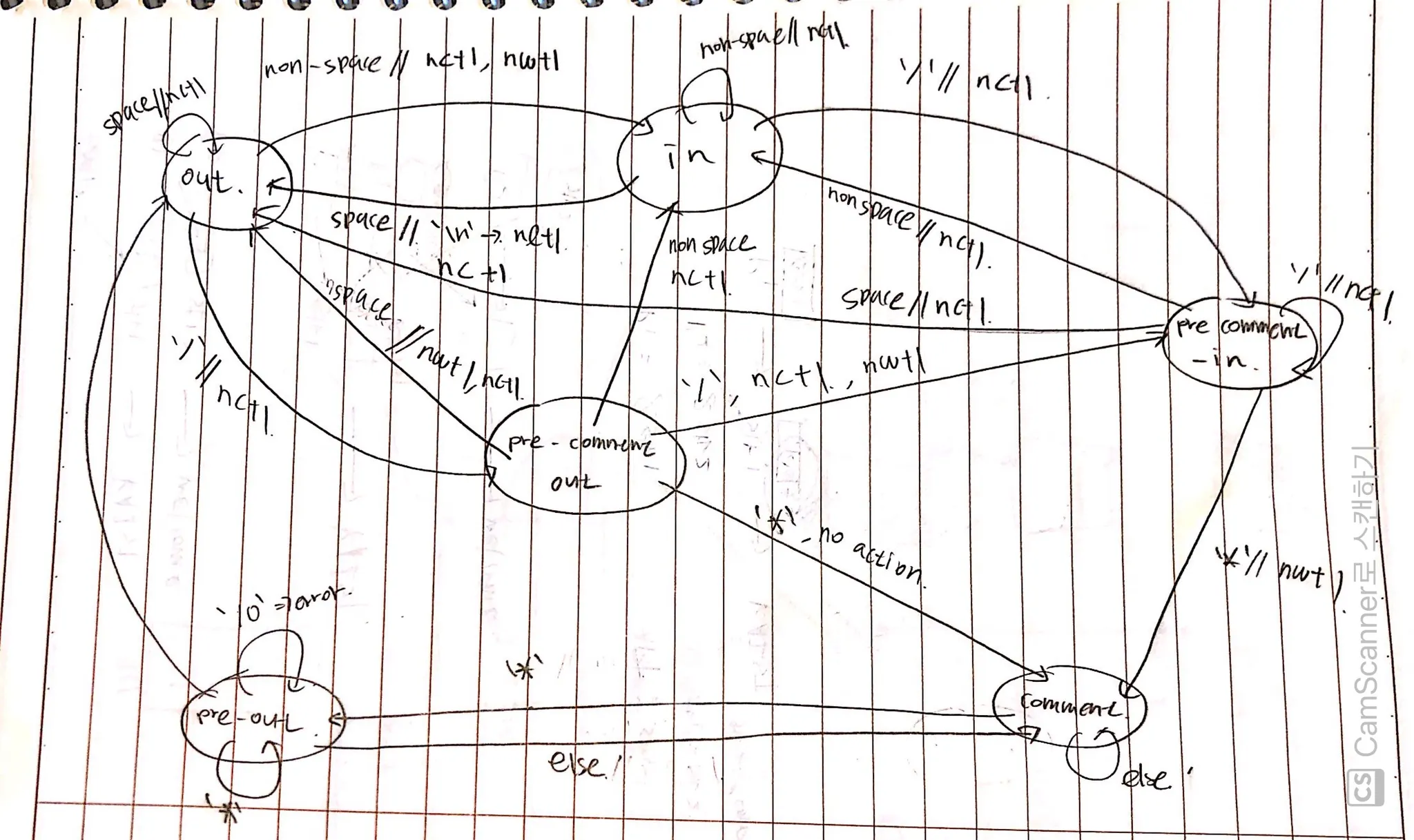
Lab1
•
DFA State를 사용하여, 단어 수 세기 프로그램을 개발
•
이때, 총 글자수, 단어 수, 줄 수를 따로 세야한다.
•
주석(/* ... */ )이 있는 경우, 안에 들어가는 글자수나 단어수는 카운트하지 않는다.
•
DFA
Lab2
•
String manuplation 함수를 구현해보자
◦
strlen, strcpy, strcmp, strstr, strcat
•
UNIX의 popular tool인 grep을 간단하게 구현한 simple grep , sgrep을 구현하자.
◦
./sgrep -f Google < google_wiki.txt
⇒ txt 파일 내의 Google이란 단어를 발견해서, 단어가 있는 line을 출력
◦
./sgrep -r Google Microsoft < google_wiki.txt > microsoft.txt
⇒ txt 파일 내의 Google 이란 단어를 Microsoft란 단어로 모두 치환
◦
./sgrep -d google_wiki.txt microsoft.txt
⇒ txt 파일 중, 다른 줄이 있다면 비교해서 출력
Lab3

•
dynamic resizing array를 구현하고, struct UserInfo를 등록, 삭제, 통계 등을 위한 interface를 구현
•
User의 id와 name에 대한 두 개의 HashTable을 구현하고, 이것에 userInfo를 등록,삭제,통계를 낼 수 있는 interface를 구현
Lab4
•
기본적인 어셈블리 코드 작성
•
stack 구조를 이용한 간단한 계산기 코드
Lab5
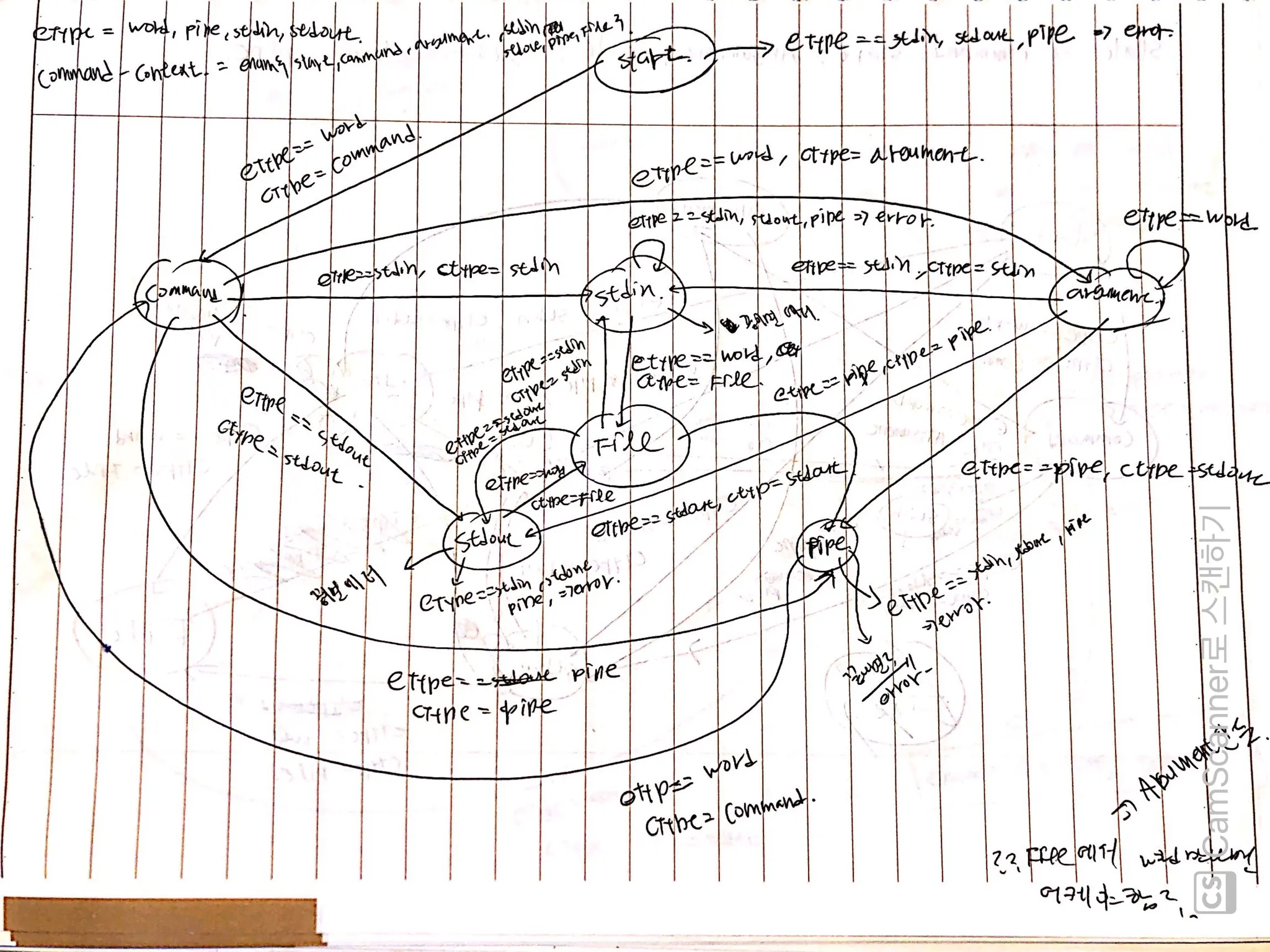
•
커맨드 라인을 받아들여서, 적절한 프로그램을 찾아 실행시키는 myShell 작성
◦
programmer error Handling
◦
Lexical analysis를 통해 들어오는 input을 단어 단위로 분해한다. 이 때, double quotes는 single token으로 취급하며, ‘|’는 special character로써 별도의 token으로 취급
◦
syntatic analysis는 쪼개진 토큰이 올바른 형식인지 확인한다.
◦
명령어 단위로 쪼갰다면, fork를 이용해 명령을 실행
◦
여러 개의 파이프와 redirection을 지원해야함.
•
DFA